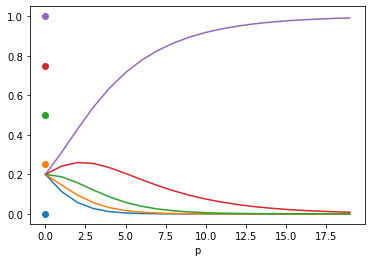
Given a tensor of values in the range [0, 1], multiplying these values with a scalar p and applying a softmax gives scaled probabilities that sum to 1. Increasing p pushes the values to either 0 or 1. See example:
values = torch.tensor([0.00, 0.25, 0.50, 0.75, 1.00])
softmax_values = torch.stack([torch.softmax(p*values, 0) for p in np.arange(0, 20)])
for input, outputs in zip(values, softmax_values.T):
c = plt.gca()._get_lines.get_next_color()
plt.plot([0], [input], 'o', c=c)
plt.plot(outputs, c=c)
plt.xlabel("p")
plt.show()
Dots represent the input values and lines show softmax values of those values given a certain p.
Setting low values of p results in all softmax values converge to 1 / n_values = 1 / 5 = 0.2.
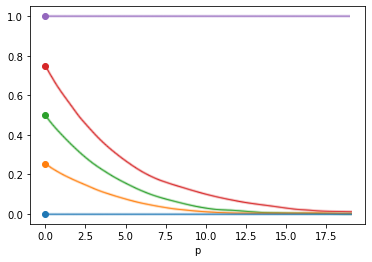
How do I instead create a function that gradually transform the input values to their softmax as p → inf?
I will try to tinker with this solution in a few hours.
Do you happen to know if torch.where breaks the gradent tree? I am looking for a differentiable function even if I know that for large values of p, the gradient will be strangled.
torch.where() does not break the computation graph – that’s a good
thing about it.
But, furthermore, in this specific case, each individual element of values
only participates in a single the branch of the torch.where() function.
I’m just using it as a more compact way to single out the largest element
in values, rather than indexing with argmax().
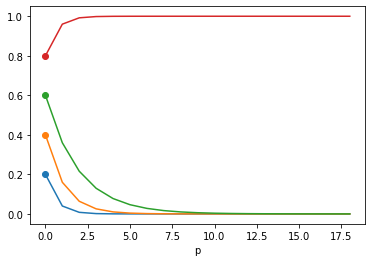
values = torch.tensor([0.20, 0.40, 0.60, 0.80], requires_grad=True)
def gradual (values, p):
return torch.where (values == values.max(), 1.0 - (1.0 - values)**p, values**p)
softmax_values = torch.stack([gradual(values, p) for p in np.arange(1, 20)])
for input, outputs in zip(values, softmax_values.T):
c = plt.gca()._get_lines.get_next_color()
plt.plot([0], [input], 'o', c=c)
plt.plot(outputs.detach(), c=c)
plt.xlabel("p")
plt.show()
loss = softmax_values.mean()
loss.backward()
values.grad
tensor([0.0206, 0.0365, 0.0822, 0.0206])
Do you know if that is the case generally, that using torch.where(x == max(x), t1, t2) is differentiable while torch.argmax(x) is not? I guess they have different use-cases but this feels like a very nice “trick” to maintain gradient.