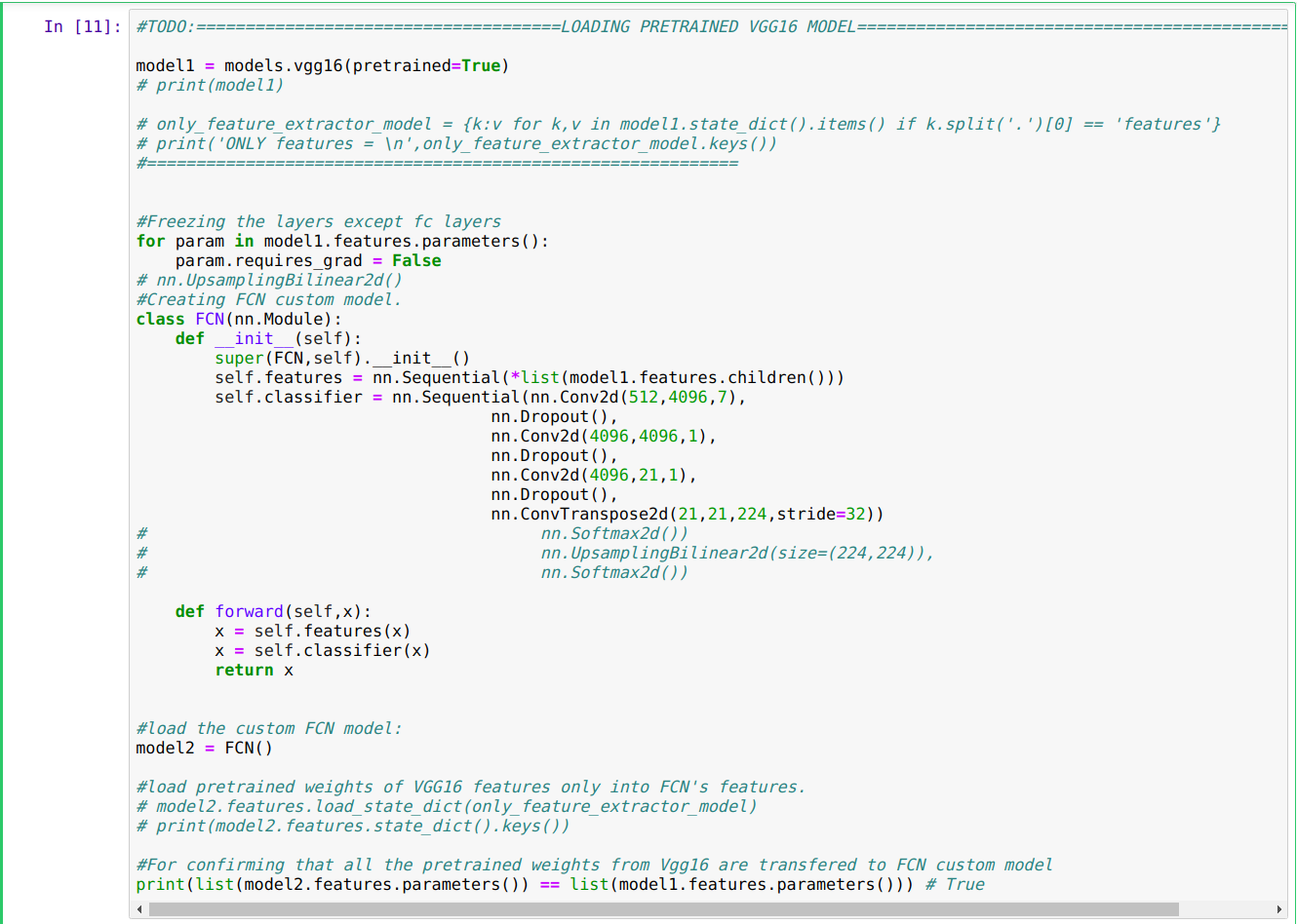
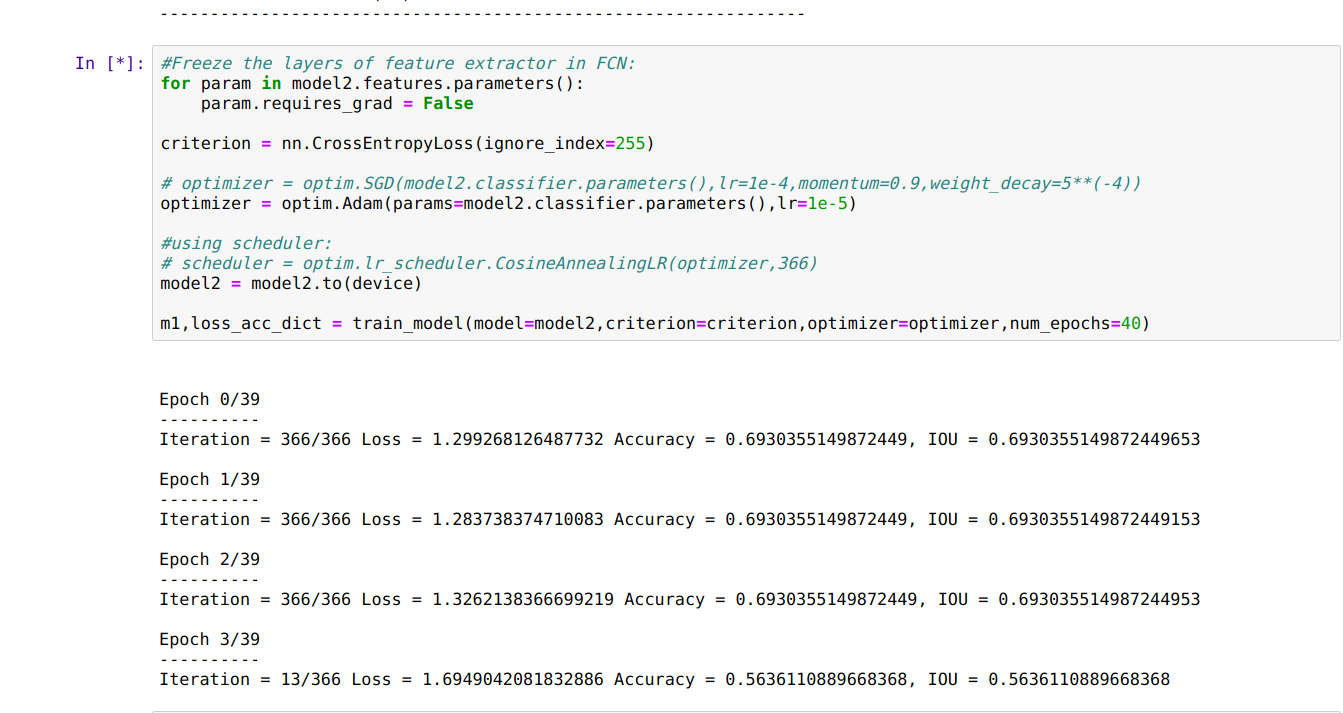
I am currently working on pascal voc 2012 dataset. I am a bit confused regarding the Normalization of images. Do I need to normalize the ground-truth labels, if I am normalizing my input images?
For experimentation, I tried to normalize the ground-truth labels for the corresponding input images using transforms.Normalize() function. When I try to train my network I get an error:
RuntimeError Traceback (most recent call last)
<ipython-input-12-416ca5ee56ac> in <module>()
10 model2 = model2.to(device)
11
---> 12 m1,loss_acc_dict = train_model(model=model2,criterion=criterion,optimizer=optimizer,num_epochs=175)
<ipython-input-10-1744505e89c5> in train_model(model, criterion, optimizer, scheduler, num_epochs)
38 print(train_y)
39 loss = criterion(outputs,train_y)
---> 40 epoch_loss += float(loss)
41
42 #calculating the accuracy:
RuntimeError: cuda runtime error (59) : device-side assert triggered at /opt/conda/conda-bld/pytorch_1535491974311/work/aten/src/THC/generic/THCStorage.cpp:36
Here is my code for train helper function:
#Create a function for training a model.
def train_model(model, criterion, optimizer, scheduler=None, num_epochs=10):
# since = time.time() #Start the timer
model.train() #Put in train mode.
total_acc = []
total_loss = []
total_iou = []
for epochs in range(num_epochs):
epoch_loss = 0.0
epoch_acc = 0
epoch_iou = 0
print('\n')
print("Epoch {}/{}".format(epochs,num_epochs-1))
print('-'*10)
iteration = 0
total_iteration = train_images_dataloader.__len__()
for batch, data in enumerate(train_images_dataloader):
#Keeping count of currect iteration
iteration += 1
#loading the data on the GPU:
train_x, train_y = data['image_x'].to(device), data['image_y'].to(device)
#zero the parameter gradients:
optimizer.zero_grad()
#forward pass:
outputs = model(train_x)
#compute loss:
train_y = train_y.squeeze().long()
print(train_y)
loss = criterion(outputs,train_y)
epoch_loss += loss
#calculating the accuracy:
_, predicted_indices = torch.max(outputs,1)
total = train_y.size(0)*train_y.size(1)*train_y.size(2)
correct = (predicted_indices == train_y).sum().item()
acc = (correct/total)
epoch_acc += float(acc)
m_iou = compute_iou(predicted_indices,train_y)
epoch_iou +=m_iou
print('Iteration = {}/{} Loss = {} Accuracy = {}, IOU = {}'.format(iteration,total_iteration,loss.item(),acc,m_iou),end="\r")
#back-propogate:
loss.backward()
#update the weights:
optimizer.step()
#Memory management:
del outputs,train_x,train_y
writer.add_scalar('Train/Loss',epoch_loss/total_iteration,global_step=epochs)
writer.add_scalar('Train/Accuracy',(epoch_acc/total_iteration)*100,global_step=epochs)
writer.add_scalar('Train/Mean IOU',(epoch_iou/total_iteration),global_step=epochs)
total_acc.append(epoch_acc/total_iteration)
total_loss.append(epoch_loss/total_iteration)
total_iou.append(epoch_iou/total_iteration)
print('\n')
print('Total accuracy = ',sum(total_acc)/num_epochs)
print('Total Loss = ',sum(total_loss)/num_epochs)
print('Total mean IOU = ',sum(total_iou)/num_epochs)
return model,{'Accuracy':total_acc,'Loss':total_loss,'mIOU':total_iou} #divide by num_opochs and then sotre in dict.
Custom dataset loader:
#Creating custom dataloader fro PASCAL VOC 2012
'''
__init__ : class variables such as, images_path, transform etc.
__len__ : would return len of the entire dataset
__getitem__ : returns ith image from the dataset
'''
class PascalVocDataset(Dataset):
def __init__(self,anno_path,ip_images_path,seg_images_path,transform=None):
'''
anno_path = path to train.txt file for image identifers
ip_images_path = path to input image folders
seg_images_path = path to segmentation maps class folder
'''
self.anno_path = anno_path
self.ip_images_path = ip_images_path
self.seg_images_path = seg_images_path
self.transform = transform
def getImagesNames(self,path):
#Returns image identifiers from file_name
#path = .txt location
images_names = []
with open(path) as fp:
images_names = list(map((lambda x: x[:-1]),fp.readlines()))
fp.close()
return images_names
def __len__(self):
return len(self.getImagesNames(self.anno_path))
def __getitem__(self, idx):
file_names = self.getImagesNames(self.anno_path)
file_path_x = self.ip_images_path+file_names[idx]+'.jpg'
file_path_y = self.seg_images_path+file_names[idx]+'.png'
#X images:
im = Image.open(file_path_x)
image_x = im.convert('RGB')
#Y images:
img = Image.open(file_path_y)
# img = img.resize((224,224),Image.ANTIALIAS)
# image_y = torch.tensor(np.array(img),dtype=torch.long)
sample = {'image_x':image_x,'image_y':img}
if self.transform:
sample['image_x'] = self.transform(sample['image_x'])
sample['image_y'] = self.transform(sample['image_y'])
return sample