I want to implement a linear function: y = [w_1x_1+b_1; w_2x_2+b_2;…;w_kx_k+b_k] the size of input x is (b,k*c), where b is the batch size, k is the number of groups, c is the number of channels. As shown below:
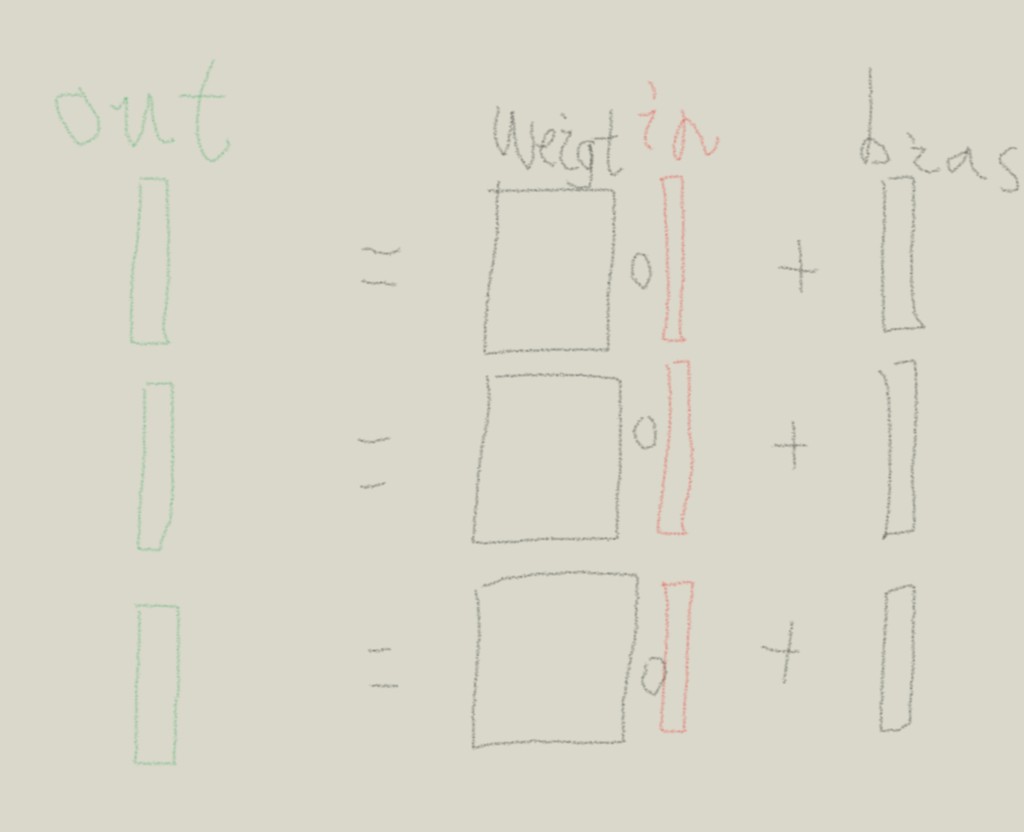
And a Grouped convolution layer is also needed. The grouped convolution layer just like using the convolution setting groups=k. The difference is that the weight and bias is not expected to be shared between groups.
Although this operation can be implemented with multiple linear or convolutional layers, I don’t think it is convenient.
Actually, I hope that different data may be processed with different weights. I want to transfer the batch to the channel, like (b, c, h, w)->(1, bxc, h, w), so that a sample corresponds to a group of channels, and each group of channels is processed with different weights. And then reshaping it back.