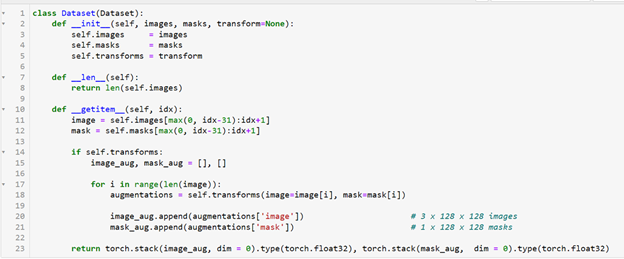
Apologies for the late reply, I was having trouble recreating the same issue. I realized that I mistook my custom Dataset I shared in my original post as the Dataloader when it isn’t. Thus, my training results were gotten from using just my Dataset class and no Dataloader. I’m assuming the memory issue was caused by not using a Dataloader, so I am now trying to get my custom Dataset to work with the Pytorch Dataloader.
Below is a simple code to test the Dataset with the Pytorch Dataloader. When I tried testing my custom Dataset, it wouldn’t execute. But when I tried using the LSTM sliding window Dataset (see link to that dataset in original post), it would execute.
Simple Execution Code for Testing (Dataset is the custom Dataset class)
from torch.utils.data import DataLoader
import albumentations as A
import numpy as np
B, H, W = 100, 32, 32 # Batch, Height, Width
imgset = np.random.rand(B,H,W,3) # Dummy numpy datasets
labset = np.random.rand(B,H,W,1)
transform = A.Compose([ToTensorV2()]) # Data transformation
trainset = Dataset(imgset, labset, transform) # Process data into trainset
dataloader = DataLoader(trainset, batch_size = 1, shuffle=False, pin_memory=True) # Dataloader
# Print each batch
for i, (img, msk) in enumerate(dataloader):
print(f"Batch {i} \tImages: {img.shape}\t Masks: {msk.shape}")
However, the LSTM sliding window Dataset didn’t make batches the way I wanted. Image A below shows what the batch outputs look like made by the LSTM sliding window Dataset. The batch outputs I am aiming to create can be seen in Image B below, which is similar to Image A but the sliding window starts with one image rather than the first batch size number of images. Note that for Image A and Image B, each row is a batch, each element is the index of one image, the maximum batch size is 4, and dataset size is 10.
Image A: Type of batches made by the LSTM sliding window Dataset :

Image B: Type of batches I want to produce:

I’m currently looking more into the Pytorch Dataloader to see if there is any way I can get the sliding window to work like in Image B (I am experimenting with a custom Batch Sampler with no success so far). If you or anyone else have any ideas or advice on achieving this, I would greatly appreciate it! Thank you!