Hello everyone,
First of all, I want to thank this community for help me out in a lot of tiny and big problems since I began using Pytorch; sadly I couldn’t find a related thread with the current problem i’m facing. I don’t have much experience with recurrent models and attention mechanisms, that’s why i can’t figure it out how can I solve it yet, that’s why i’m asking to you what may be wrong with my code.
I’m implementing a multimodal model that matches video with corresponding text descriptions by converting video-sentence pairs into a common vector space. The paper of this model is DL-61-86 at TRECVID 2017: Video-to-Text Description (it doesn’t have any public code, that’s why i’m implementing it by my own).
The part that i’m struggling to get right is the RNN and soft attention mechanism in the video branch of the model. It applies a GRU to N frames (N depending of each video) of the video and then uses a soft attention over the N outputs of the GRU to get a 1-D embedding of the video. My problem is with the GRU and trainable weights of the soft attention mechanism Ws, Wm and Wm. They all tend to a constant too quick (first 1-2 iterations) in the training process, ignoring the video branch input and making the output vector of the branch almost zero in every value.
This are the tensorboard histrogram of this weights during training.
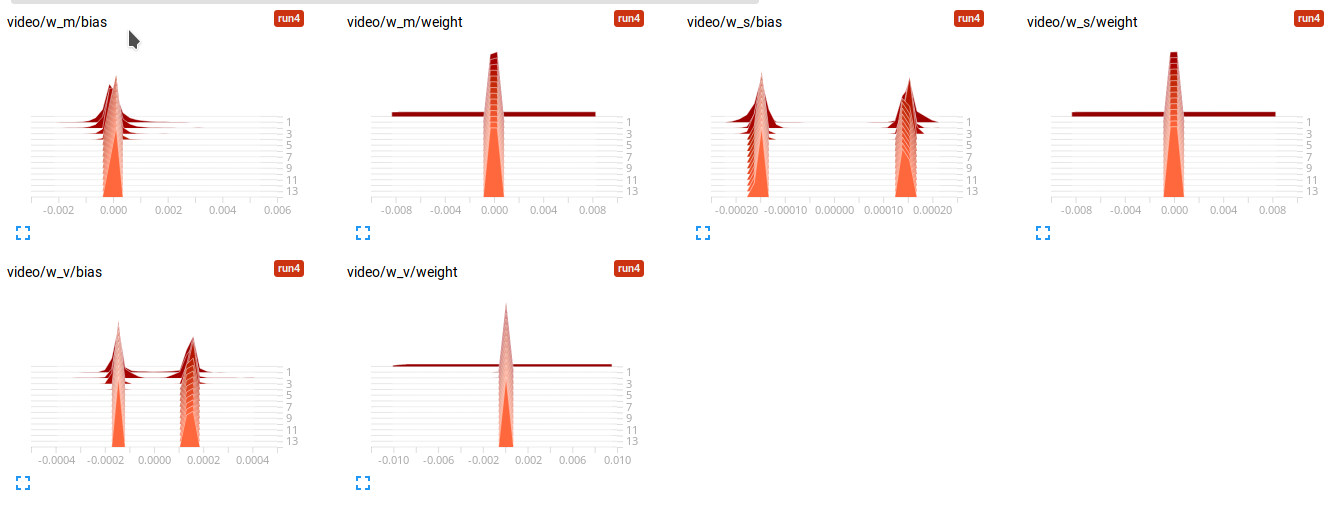

My implementation of the video branch is this, please focus on the soft attention part where I iterate over the batch. I commented the sizes of the layers and tensors in the forward method for easier read.
def xavier_init(fc):
r = np.sqrt(.6) / np.sqrt(fc.in_features + fc.out_features)
fc.weight.data.uniform_(-r, r)
if fc.bias is not None:
fc.bias.data.fill_(0)
class VideoBranch(nn.Module):
# 2048 2048 512 'gpu:0'
def __init__(self, resnet152_dim, hidden_dim, video_out_dim, device):
super(VideoBranch, self).__init__()
self.device = device
self.gru = nn.GRU(resnet152_dim, hidden_dim)
self.w_v = nn.Linear(resnet152_dim, hidden_dim * 2) # 2048 x 4096
self.w_s = nn.Linear(hidden_dim * 2, hidden_dim * 2) # 4096 x 4096
self.w_m = nn.Linear(hidden_dim * 2, hidden_dim * 2) # 4096 x 4096
self.dropout_1 = nn.Dropout(0.2)
self.dense_1 = nn.Linear(hidden_dim * 2, video_out_dim) # 4096 x 512
self.dense_1_bn = nn.BatchNorm1d(video_out_dim) # 512
self.dropout_2 = nn.Dropout(0.2)
self.dense_2 = nn.Linear(video_out_dim, video_out_dim) # 512 x 512
self.dense_2_bn = nn.BatchNorm1d(video_out_dim) # 512
xavier_init(self.w_v)
xavier_init(self.w_s)
xavier_init(self.w_m)
xavier_init(self.dense_1)
xavier_init(self.dense_2)
def forward(self, resnet152_vectors, n_frames): # [B, M, 2048] , [B,]
# M is the maximum of frames extracted from video in the dataset, if a video
# has N < M frames, its embedding (a list of tensors of dimension 2048) is padded with
# M - N zero tensors of size 2048 at the end of the list. This allows to iterate using a
# DataLoader (all inputs of the same size)
# packing the input vectors of the GRU for computation efficiency
embs = pack_padded_sequence(resnet152_vectors, n_frames, batch_first=True, enforce_sorted=False)
gru_out_packed, _ = self.gru(embs)
# Getting the output of the GRU for each video, they are padded to
gru_out = pad_packed_sequence(gru_out_packed, batch_first=True)[0]
# soft attention mechanism
# since every embedding in the batch has different number of frames N,
# and the attention mechanism works with the mean of the gru output of each video,
# i can't make computations by batch and i have to iterate on every video of the batch,
# so first i crop the padded zero tensors the 'pad_packed_sequence' added and I apply the soft
# attention video by video. This is the part that i'm worried about because maybe by
# iterating over the batch, the gradient is applied multiple times on the trainable weights
# of the attention mechanism (Wm, Ws and Wv), modifing its values more than necessary.
v_a = None
for i in range(resnet152_vectors.size(0)):
# s is the concat of the every GRU output (2048-d tensor) of the video with its corresponding input (2048-d tensor).
# size: [N, 4096]. N different for every video.
s = torch.cat((gru_out[i, :int(n_frames[i]), :], resnet152_vectors[i, :int(n_frames[i]), :]), 1)
v = torch.mean(resnet152_vectors[i, :int(n_frames[i]), :], dim=0) # [2048]
y_s = nn.Tanh()(self.w_s(s)) # [N, 4096]
y_v = nn.Tanh()(self.w_v(v)) # [4096]
m = torch.mul(y_s, y_v) # [N, 4096]
r = self.w_m(m) # [N, 4096]
alpha = nn.Softmax(dim=1)(r) # [N, 4096]
# v_a is the final vector of the attention where i concat every final 4096-d vector of each
# video and get a final [B, 4096] to continue making calculation by batch
if i == 0:
v_a = torch.sum(torch.mul(alpha, s), dim=0).unsqueeze(0) # [1, 4096]
else:
v_a = torch.cat((v_a, torch.sum(torch.mul(alpha, s), dim=0).unsqueeze(0)), dim=0)
# latent space conversion
y = self.dropout_1(v_a) # [B, 4096]
y = self.dense_1(y) # [B, 512] and so on...
y = self.dense_1_bn(y)
y = nn.ReLU()(y)
y = self.dropout_2(y)
y = self.dense_2(y)
y = self.dense_2_bn(y)
y = nn.ReLU()(y)
return y #[B, 512]
I know this may be a hard problem to solve, but I want to discard any implementation mistakes, because i’ve looked up and fixed every other aspect (training data, training process, loss function, etc) and i can’t get this model to work as intended yet.
Thanks you very much for your time.