I am trying to implement a time-series forecasting algorithm using pytorch internal gru module.
However, I am a bit confused when it comes to choosing the correct output for my specific use-case.
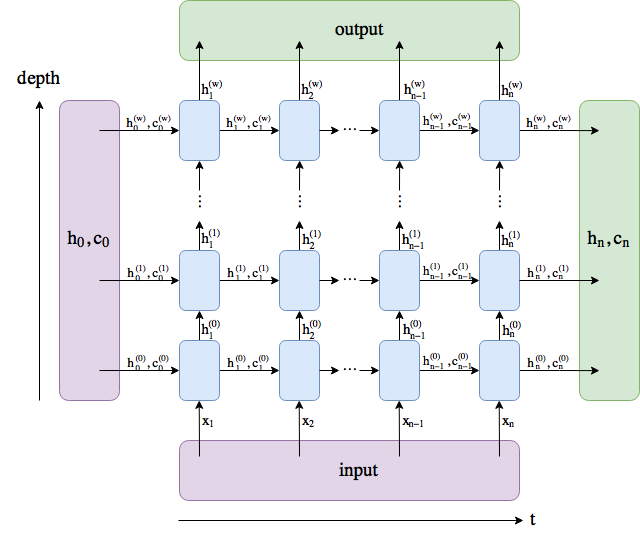
After searching for answers I came across this picture, which clarified some things for me.
Problem definition:
I have a time-series of lagged, hourly price-data, let´s say 24*7 = 168 datapoints as input.
I then want to predict the next 24 timesteps.
However, I am unsure which output i should use in this case.
Should I use the last hidden state of the last layer of the GRU network ?
Edit: Or should I use the hidden state (=output) of every GRU cell in the network ?
I don’t think that there is a clear-cut reason why to choose one solution over the other.
The basic sequence-to-sequence setup is to encode the input sequence as the last hidden state, and give it to the decoder as its first hidden state.
However, nobody is stopping you to use the outputs of all time steps – and probably do some max or average pooling, or push it through a linear layer (as all your input sequences seem to have the same length) – and give this to the decoder as its first hidden state.
I think I once tried “last hidden state” vs. “max/avg pooling” for an LSTM/GRU-based classifier with similar results. But that’s just purely anecdotal, and might differ much more in your case.
I would simply try both approaches and see what happens, the differences to the code are only 2-3 lines of codes anyway.