I am trying to build a model which is going to predict a BUY or SELL signal from stocks using reinforcement learning with Actor-Critic policy.
I’m new to machine learning and PyTorch in general and in my research of the problem I’ve realized that I am not learning anything in a way… What I mean by that is, if I am just watching how the wandb graphs are evolving then it looks like am learning something.
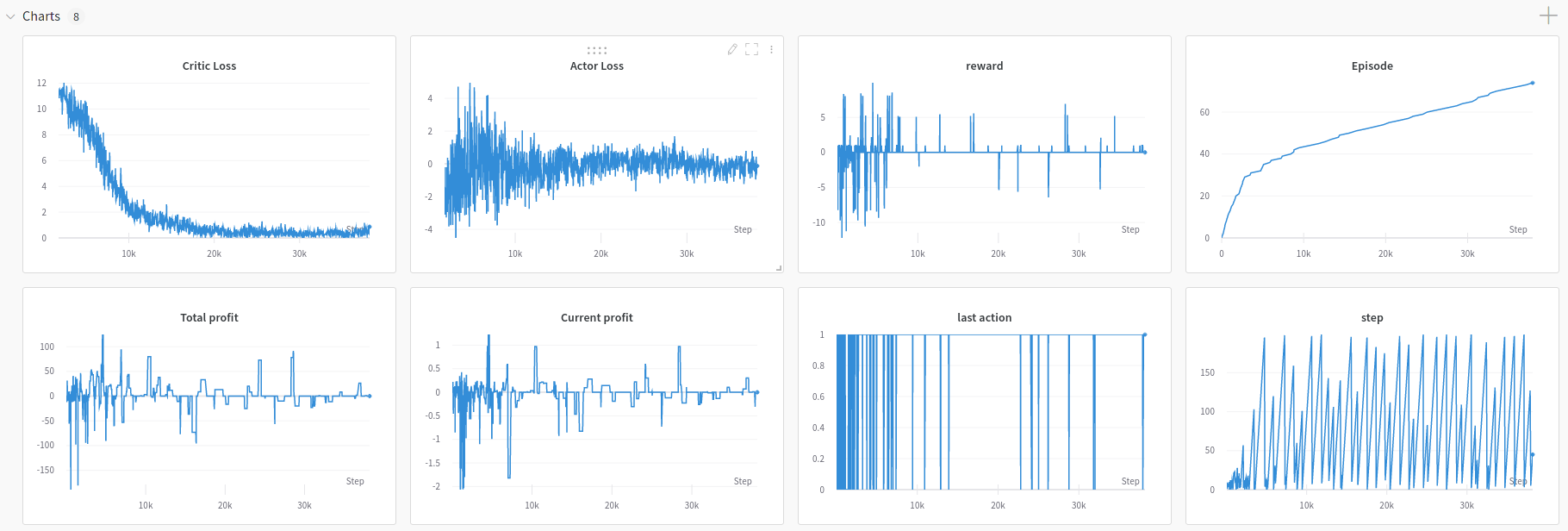
also, I am saving and loading the model by these 2 functions:
def save_model(self, path: str, name: str):
torch.save(self.actor.state_dict(), os.path.join(path, f"{name}_actor"))
torch.save(self.critic.state_dict(), os.path.join(path, f"{name}_critic"))
def load_model(self, path: str, name: str):
self.actor.load_state_dict(torch.load(os.path.join(path, f"{name}_actor")))
self.critic.load_state_dict(torch.load(os.path.join(path, f"{name}_critic")))
But what I found really strange is that in my select action function I will ALWAYS select action 1 (sell) out of the 2 (buy or sell). The only time when the action is going to differ from 1 is when random_for_egreedy is greater then epsilon
def select_action(self, state, epsilon):
random_for_egreedy = torch.rand(1)[0]
if random_for_egreedy > epsilon:
with torch.no_grad():
state = torch.Tensor(state.values).to(device)
actor_action = self.actor(state)
action = torch.argmax(actor_action)
action = action.item()
else:
action = self.gym.action_space.sample()
return action
This is my optimize function:
def optimize(self):
if len(self.memory) < self.config.batch_size:
return
self.optimizer_actor.zero_grad()
self.optimizer_critic.zero_grad()
state, action, new_state, reward, done = self.memory.sample(batch_size=self.config.batch_size)
state = torch.Tensor(np.array(state)).to(device)
new_state = torch.Tensor(np.array(new_state)).to(device)
reward = torch.Tensor(reward).to(device)
action = torch.LongTensor(action).to(device)
done = torch.Tensor(done).to(device)
dist = torch.distributions.Categorical(self.actor(state))
advantage = reward + (1 - done) * self.config.gamma * self.critic(new_state) - self.critic(state)
critic_loss = advantage.pow(2).mean()
self.optimizer_critic.zero_grad()
critic_loss.backward()
self.optimizer_critic.step()
actor_loss = -dist.log_prob(action) * advantage.detach()
self.optimizer_actor.zero_grad()
actor_loss.mean().backward()
self.optimizer_actor.step()
wandb.log({"Actor Loss": actor_loss.mean(), "Critic Loss": critic_loss})
And here is my training loop:
for ep in range(conf.num_episode):
state = env.reset()
step = 0
# qnet_agent.reset_running_loss()
wandb.log({"Episode": ep})
if ep % save_after_episode == 0:
qnet_agent.save_model("checkpoints", model_save_name)
while True:
wandb.log({"step": step})
step += 1
frames_total += 1
epsilon = calculate_epsilon(frames_total)
action = qnet_agent.select_action(state, epsilon)
wandb.log({"last action": action})
new_state, reward, done, info = env.step(action)
wandb.log({"Current profit": info['current_profit']})
wandb.log({"Total profit": info['total_profit']})
wandb.log({"reward": reward})
memory.push(state, action, new_state, reward, done)
qnet_agent.optimize()
state = new_state
if done:
steps_total.append(step)
break
Could any of you tell me if I missed something? Or I am doing something wrong?