I am bulding a model for tweet sentiment classification.
I initially used gensim to learn word2vec representation of my dataset.
I have set embedding size to 32
eg:
**sentence**:
['Have', 'you', 'tried', 'adding', 'yourself']
**word2vec representation from gensim:**
tensor([[ 1.4620e-01, -8.5515e-01, 1.4198e+00, 3.4828e+00, -3.3035e-01,
3.4886e-01, 3.8095e+00, -3.5703e+00, 2.7998e+00, -2.9370e+00,
2.9146e+00, -3.6229e-01, 3.4922e+00, 1.8544e+00, 3.1512e+00,
4.9468e+00, -2.1402e+00, 2.5461e+00, -1.9959e+00, 2.0394e-01,
2.7256e-01, 9.4945e-01, 2.9587e+00, 5.5111e+00, 5.1617e+00,
-2.9875e+00, 2.2928e+00, -1.6469e+00, 3.2937e-01, 2.4262e+00,
1.7776e+00, -3.5884e+00],
[-6.4258e+00, -1.1460e+00, 4.4689e+00, 4.4227e+00, -2.8765e-01,
2.6317e+00, 5.6104e-01, -2.6672e+00, -2.3151e-01, -1.4247e+00,
-7.8311e+00, 3.4394e+00, -3.8948e+00, 5.1647e+00, -5.1729e+00,
-3.3228e-01, 1.5289e+00, -9.3406e-03, -1.1680e+00, -3.3537e+00,
7.4931e+00, 8.0219e-01, -2.1190e+00, -4.0652e-01, -3.2117e-01,
2.4333e+00, 1.4425e+00, 1.8844e+00, 1.6728e+00, 3.0737e+00,
3.6921e+00, 2.0336e+00],
[ 1.1453e+00, 1.7200e+00, 1.5659e-01, 2.0237e+00, 1.3018e+00,
-2.8969e+00, 7.6323e-02, -7.1022e-01, 2.4552e+00, 1.4979e+00,
-7.8366e-01, -1.0592e+00, 7.1787e-01, -1.4309e+00, -6.0945e-01,
2.0332e+00, 5.0113e+00, 7.0676e-01, 2.0374e-01, -2.9717e+00,
4.2711e-01, -1.7514e+00, -1.6970e+00, -4.4132e+00, 2.3952e-01,
7.6439e-01, -2.8841e+00, -4.6913e+00, -1.1418e+00, -4.0310e+00,
3.0588e+00, -2.1230e+00],
[-1.3288e+00, 6.3822e-01, 3.4908e-01, 1.9915e+00, 3.9657e-01,
-7.8983e-01, -2.8086e-01, -5.7929e-01, 2.0741e+00, -1.2884e+00,
-2.5335e+00, -2.1533e-02, 2.0698e+00, -3.9439e-03, 2.5604e-01,
-2.1838e+00, 1.3293e-01, 3.4999e-01, -2.3387e+00, -2.0124e+00,
1.7638e+00, 3.6158e-01, 1.7742e+00, -4.8334e-01, -2.5748e+00,
-2.7936e+00, 2.7674e-01, -2.0076e+00, -1.5897e+00, -1.1462e+00,
-3.3607e-01, -4.0830e-01],
[-4.8255e-01, 8.9328e-01, 1.1424e+00, 2.7374e+00, -1.3206e+00,
5.2367e-01, 8.1122e-03, -2.6338e+00, -2.1248e+00, -2.3494e+00,
-3.9087e+00, -3.9225e-01, -1.9196e+00, 2.0214e+00, -2.1552e+00,
3.0173e-01, 2.9504e+00, 3.2806e-01, 5.9682e-01, -8.2841e-01,
1.8790e+00, 1.7234e+00, 5.6904e-01, -1.1782e+00, 1.3931e+00,
2.6821e+00, 5.2979e-02, -3.8034e+00, -6.0337e-01, 2.8629e+00,
4.1186e+00, -5.8047e-01]])
**shape**:
(5, 32)
Now I am using torch.nn.utils.rnn.pack_padded_sequence to pass this word2vec representations as input to gru.
But it seems that its not learning, is there issue in the pretrained word2vec representations?
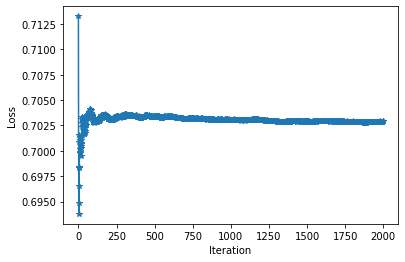
I also tried to increase the embedding size from 32 to 100 but its still not learning.