Yeah sure
Here’s the implementation:
Model:
class SentimentAnalysisModel(nn.Module):
def __init__(self,vocab_size,embedding_dim=128,hidden_dim=256,num_layer=2,pad_id=0,dropout=0.5):
super().__init__()
self.embedding=nn.Embedding(vocab_size,embedding_dim,padding_idx=pad_id)
self.GRU=nn.GRU(embedding_dim,hidden_dim,num_layer,batch_first=True,dropout=dropout)
self.linear=nn.Linear(hidden_dim,1)
def forward(self,input_ids):
embedded=self.embedding(input_ids)
output,hidden=self.GRU(embedded)
last_hidden=hidden[-1]
out=self.linear(last_hidden)
return out
Training loop:
# loss1=[] #Only initialize these lists once, First Time, to avoid resetting the checkpoint values
# epoch1=[]
# accuracy=[]
best_val_loss=float('inf')
for epoch in tqdm(range(start_index, start_index)): # Change the range to start_index + number_of_epochs to continue training for more epochs
loss_epoch=0
count=0
accuracy_epoch=0
total=0
valid_loss_acc=0
valid_count=0
model.train()
for x,y in train_dataloader:
x=x.to(device)
y=y.to(device)
optimizer.zero_grad()
output=model(x)
loss=loss_fn(output,y)
loss.backward()
optimizer.step()
loss_epoch+=loss.item()
accuracy_epoch+=Accuracy(y,output)
total+=y.size(0)
count+=1
loss1.append(loss_epoch/count)
epoch1.append(epoch)
accuracy.append(accuracy_epoch/total)
model.eval()
for x,y in validation_dataloader:
with torch.inference_mode():
x=x.to(device)
y=y.to(device)
valid_output=model(x)
valid_loss_acc+=loss_fn(valid_output,y).item()
valid_count+=1
valid_loss=valid_loss_acc/valid_count
if valid_loss<best_val_loss:
best_val_loss=valid_loss
torch.save({
'epoch': epoch,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': loss_epoch/count,
'accuracy': accuracy,
'epoch1': epoch1,
'loss1': loss1
},"/content/drive/MyDrive/RNN/IMDB/checkpoint.pth")
Loss/optimizer:
optimizer=torch.optim.Adam(model.parameters(),lr=1e-3,weight_decay=1e-5)
loss_fn=nn.BCEWithLogitsLoss()
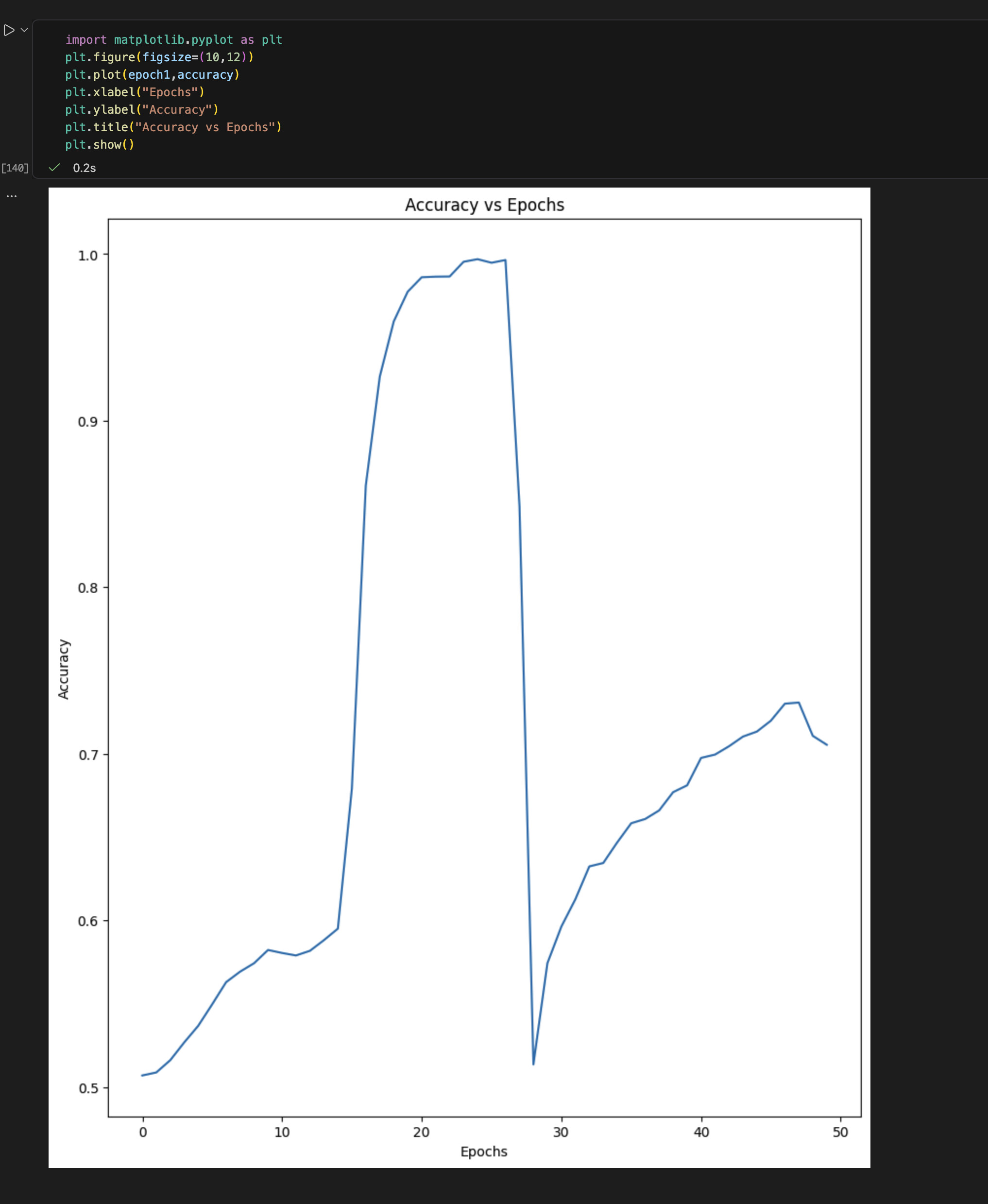
I’ve never encountered something like this before. I think it’s the high dropout value thats pushing the model off the minima, but I am not sure.
Would appreciate any suggestions on what might be causing the instability.
I’ll also try a single-layer GRU as you suggested.