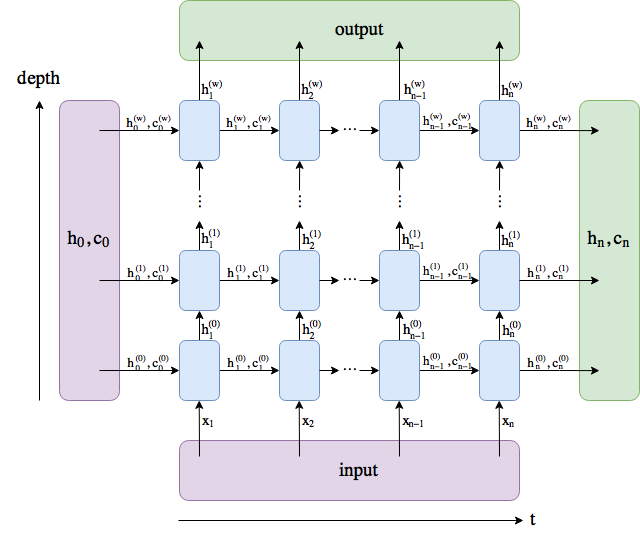
Hello,
I created this model to adapt both GRU and bidrectional GRU, would it be the correct way? Because I don’t understand Bidirectional GRU completely…
Here are the snippets where I change according to if it is bidirectional or not:
class MySpeechRecognition(nn.Module):
"""
The RNN model that will be used to perform Sentiment analysis.
"""
def __init__(self, input_size, output_size, hidden_dim, n_layers, n_feats, drop_prob=0.5, bidir=False):
super(MySpeechRecognition, self).__init__()
#output_dim = will be the alphabet + '' and space = 28 chars
self.input_size = input_size
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.drop_prob = drop_prob
self.output_dim = output_size
self.bidir = bidir
# GRU Layer --> input (batch, channel*features, time)
# Input size = number of features
self.gru = nn.GRU(input_size, hidden_dim, n_layers, batch_first=True, dropout=drop_prob, bidirectional=bidir)
# shape output (batch, channel*features, time * hidden_size)
self.layer_norm = nn.LayerNorm(n_feats)
# (batch, channel, features, time)
#Fully Connected
**if self.bidir:**
** self.fc1 = nn.Linear(self.hidden_dim*2,512)**
** else:**
** self.fc1 = nn.Linear(self.hidden_dim,512)**
self.fc2 = nn.Linear(512, self.output_dim)
self.dropout = nn.Dropout(0.2)
def forward(self, x, hidden):
# Forward function is same for both!
def init_hidden(self, batch_size):
''' Initializes hidden state '''
# Create two new tensors with sizes n_layers x batch_size x hidden_dim,
# initialized to zero, for hidden state and cell state of LSTM
weight = next(self.parameters()).data
**if (self.bidir):**
** self.n_layers = self.n_layers*2**
if (train_on_gpu):
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_()).cuda()
else:
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_())
return hidden
Additionally to that question, if I have a tensor of (32, 1, 128, 250) [It is melspectrogram], which I understand is → [Batch, Channel, Height, Width]. In this case, which would be the x0, x1, x2 (shown in picture) in the GRU? The Height or the Width?