Newbie here: I need your help understand what is happening with the model. I have a very simple GRU in pytorch that is failing because at some point, somewhere between 80 and 1000 steps, the gards become NaN, specially on the gru.weight_ih_l0.
822 gru.weight_ih_l0 --> tensor([[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
...,
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan],
[nan, nan, nan, ..., nan, nan, nan]], device='cuda:0')
I have tried using torch.nn.utils.clip_grad_norm_ however does not fix the problem. I dont think this is an exploding gradient problem, because the immediate previous step before becoming NaNs, the grads are not big, in fact, they are pretty small: grads values:
821 gru.weight_ih_l0 --> tensor([[-1.6849e-05, -2.3573e-05, -1.7454e-05, ..., -5.8837e-05,
-4.0487e-05, -1.1453e-04],
[-8.1473e-06, -1.2032e-05, -8.0858e-06, ..., -3.1780e-05,
-7.7298e-06, -6.6712e-05],
[ 7.7885e-07, -6.8368e-07, 1.0416e-06, ..., -4.8091e-06,
1.2153e-05, -4.5846e-06],
...,
[-1.4127e-04, -2.4821e-04, -1.2103e-04, ..., -8.1012e-04,
4.7487e-04, -1.2947e-03],
[-1.4756e-04, -3.2470e-04, -1.1184e-04, ..., -1.1347e-03,
7.2785e-04, -8.1474e-04],
[-3.0845e-04, -5.7420e-04, -2.8238e-04, ..., -1.8029e-03,
6.5397e-04, -2.7119e-03]], device='cuda:0')
I have tried to visualize the grads using tensorboard, however I dont fully understand the output:
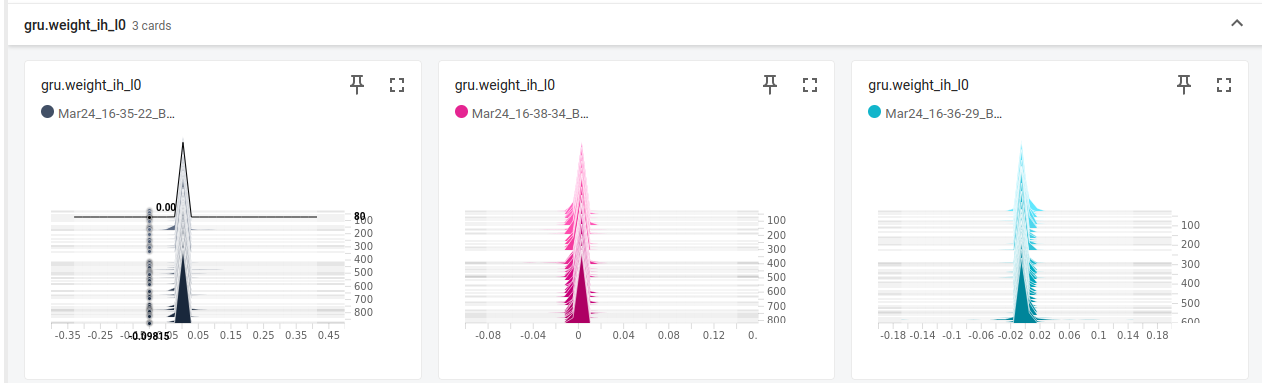
This is the model architecture:
class GRU(nn.Module):
def __init__(self, input_size, hidden_size):
super(GRU, self).__init__()
self.hidden_size = hidden_size
self.gru = nn.GRU(input_size, hidden_size)
self.fc = nn.Linear(hidden_size, 5)
def forward(self, x):
out, _ = self.gru(x)
out = out[:, -1, :] # Select last hidden state
out = self.fc(out)
return out
Any help is greatly appreciated. Thank you!