I’ve been working with the EfficientNet architecture lately and I wanted to apply Captum’s GuidedGradCam on it but I am getting strange results:
This is the code that I’m using:
from models.efficientnet import EfficientNet
import torch
import PIL.Image
from matplotlib import pyplot as plt
from torchvision.transforms import ToTensor, Resize, Compose, ToPILImage
from dataset_fun import get_data
device = 'cpu' ## Let's just put this to CPU for simplicity
model = EfficientNet.from_pretrained('efficientnet-b2', num_classes=2)
model.load_state_dict(torch.load(
'$PATH_TO_MODEL/pre_trained_model.pt'))
df = get_data() # Getting my data
df = df[df['label'] == 1]
transforms = Compose([Resize((224, 224)), ToTensor()])
model = model.to(device)
model.eval()
# Here I Instantiate the grad cam class as well as the desired layer to compute the gradients
grad_cam_layer = model._conv_head # Last convolutional layer of the EfficientNet
guided_fc = attr.GuidedGradCam(model, grad_cam_layer)
for filename in df['filename'].values.tolist():
# Some due pre-processing
im = PIL.Image.open(filename)
im = im.convert('RGB')
im = transforms(im).unsqueeze(0).to(device)
# Obtain attributes
attributes = guided_gc.attribute(im, 1)
# Plot them on screen
plt.imshow(ToPILImage()(attributes[0])) # We convert to PIL and show it on screen
plt.show()
plt.clf() # will make the plot window empty
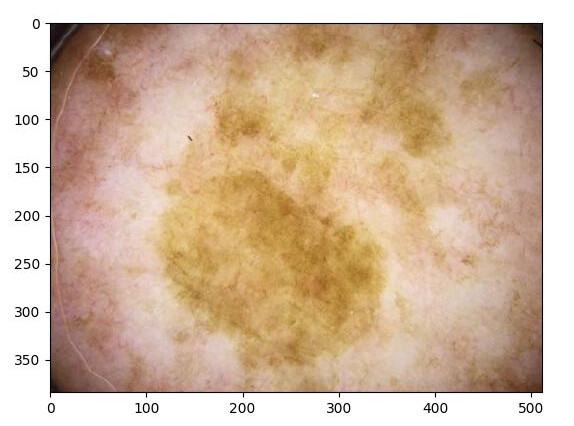
Below I show the photo that was sent to the model and the returned GradCam (I know the photos aren’t pretty, skin cancer isn’t beautiful). As it can be seen, the result doesn’t provide much information.
Dissecting the EfficientNet I’ve seen that it doesn’t use any nn.ReLU but rather a novel non-linear function named Swish. Could this be causing the error as in the Captum implementation they mention that the ReLUs have to be of a specific type.
Any help on how to properly compute the Guided Gradient Cam of an image using Captum would be appreciated.
Caveat: I know the first image is bigger, but it gets resized in the transform.
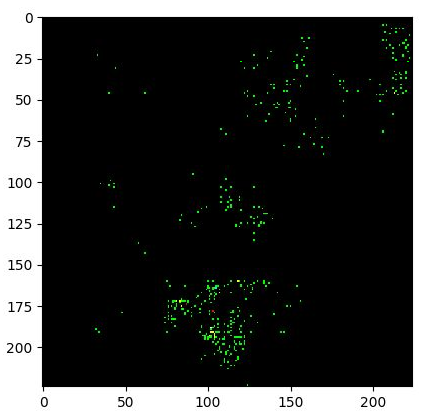
Advances:
I managed to change the Swish to a nn.ReLU() with the following code:
for i in range(len(model._blocks)):
model._blocks[i]._swish = nn.ReLU()
model._swish = nn.ReLU()
The problem is that it now outputs a complete black square.
Althought this is the recommended activation function, the model wasn’t trained with it.
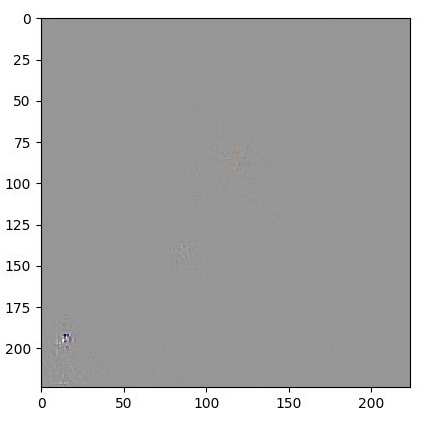
{kind=link}