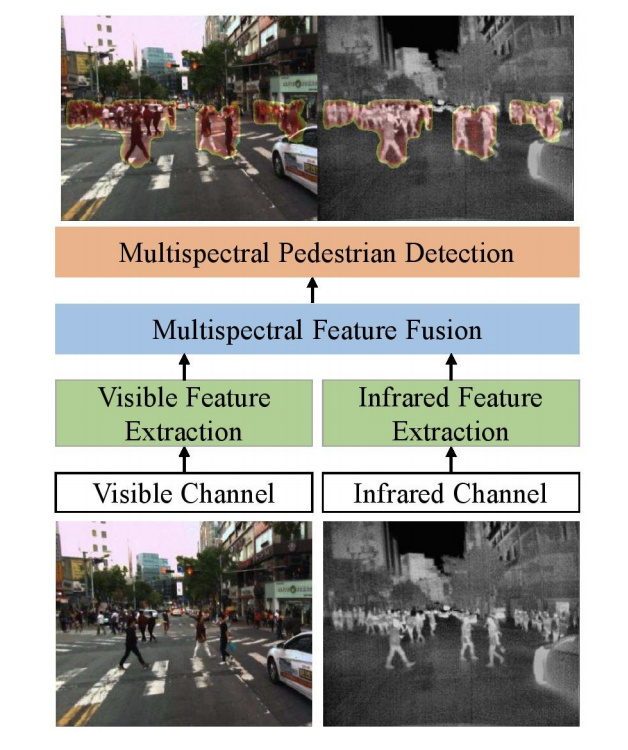
I am attempting to create a model for halfway fusion using visual and thermal data. The following is the model:
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 53 * 53, 157)
self.fc2 = nn.Linear(157+157, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x1, x2):
x1 = self.pool(F.relu(self.conv1(x1)))
x1 = self.pool(F.relu(self.conv2(x1)))
x1 = x1.view(x1.size(0), -1)
x1 = F.relu(self.fc1(x1))
x2 = self.pool(F.relu(self.conv1(x2)))
x2 = self.pool(F.relu(self.conv2(x2)))
x2 = x2.view(x2.size(0), -1)
x2 = F.relu(self.fc1(x2))
#print(x1.shape, x2.shape)
x3 = torch.cat((x1, x2), dim=1)
#print(x3.shape)
x3 = F.relu(self.fc2(x3))
x3 = self.fc3(x3)
return x3
net = Net()
for epoch in range(1):
running_loss = 0.0
for i, vs_data in enumerate(vs_trainloader, 0):
vs_images, vs_labels, vs_bbox = vs_data
vs_images = Variable(images).to(device)
vs_labels = Variable(labels).to(device)
for i, th_data in enumerate(th_trainloader, 0):
th_images, th_labels, th_bbox = th_data
th_images = Variable(images).to(device)
th_labels = Variable(labels).to(device)
optimizer.zero_grad()
outputs = net(vs_images.to(device), th_images.to(device))
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if i % 30 == 29: # print every 2000 mini-batches
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 30))
running_loss = 0.0
print('Finished Training Trainset')
The issue I am having is with loss = criterion(outputs, labels) line. How can I make sure that the loss is calculated properly for the two different datasets? Each image for both datasets will have its own corresponding labels.
Any advice would be greatly appreciated. Thank you in advance.