Hi, I already have the extracted features with dimensions [M, 192] where M can be any number (ex: [5, 192], [20, 192], [25, 192], etc). Would it be possible to include all of these features in the data loader with a batch size greater than 1? I have tried converting all of them to torch.Tensor and torch.stack and none of them works.
Since my goal is to put the input features into the encoder (VIT) in Masked Autoencoder, would it be better to convert them to the same dimension? Do you have any good ideas on how to convert?
Could you explain how you would like to use this data?
From the technical point of view you could pad the data before trying to stack it, but I think the more important part would be what the data represents and how the model should use it for its training.
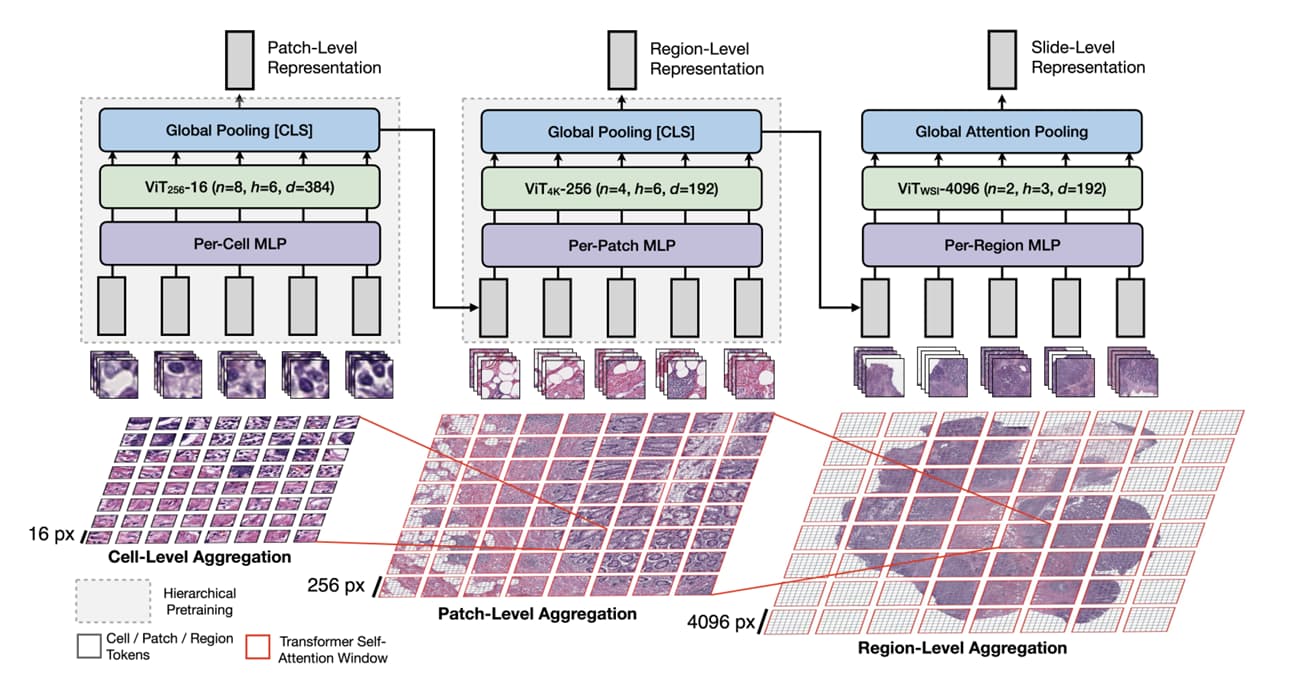
The region-level representations are already available from the output of the CLS token in the second stage, and since a Whole Slide Image can have any number of regions [4096, 4096], the representations of whole slide images now look like [5, 192], [20. 192], [100. 192]. Note that in this case, I just concat all of the regions that belong to one slide together.
Now, I want to train a masked autoencoder ([2111.06377] Masked Autoencoders Are Scalable Vision Learners) in the third stage for making a Whole Slide Image pertaining model and the inputs are based on the extracted regions that I got before. Is it possible to do that?