Hi,
I’m trying to speedup my training process in the following way: I do the first forward of my model in no_grad mode. Then I calculate the loss, and do the backward. Once the backward arrives at the output of the model forward, I resample, lets say, 30% of the inputs based on their output gradient norm, and redo the forward pass, now building the computational graph.
I have a reason to believe that in my actual training problem, only a fraction of the samples induce a significant gradient, hence this kind of scheme might be useful.
I implement this kind of logic by decorating the model.forward with this HSMWrap, which uses my HSM(torch.autograd.Function) to carry out the logic (see the code).
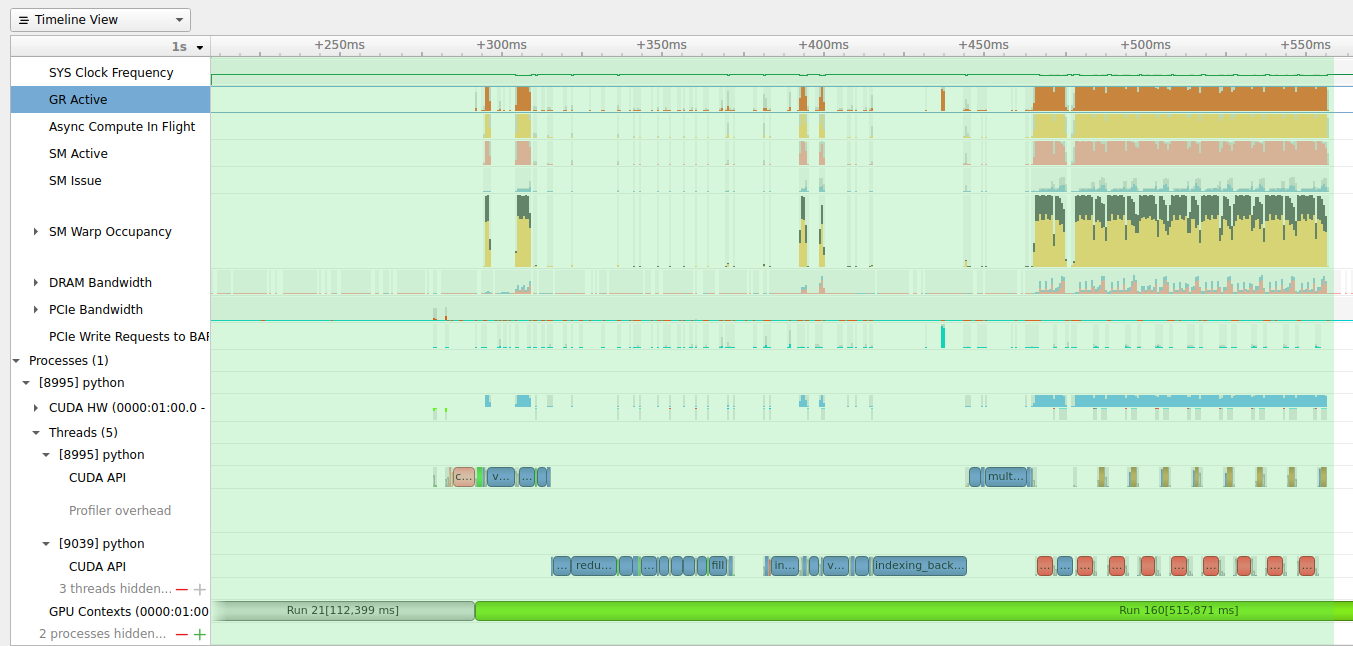
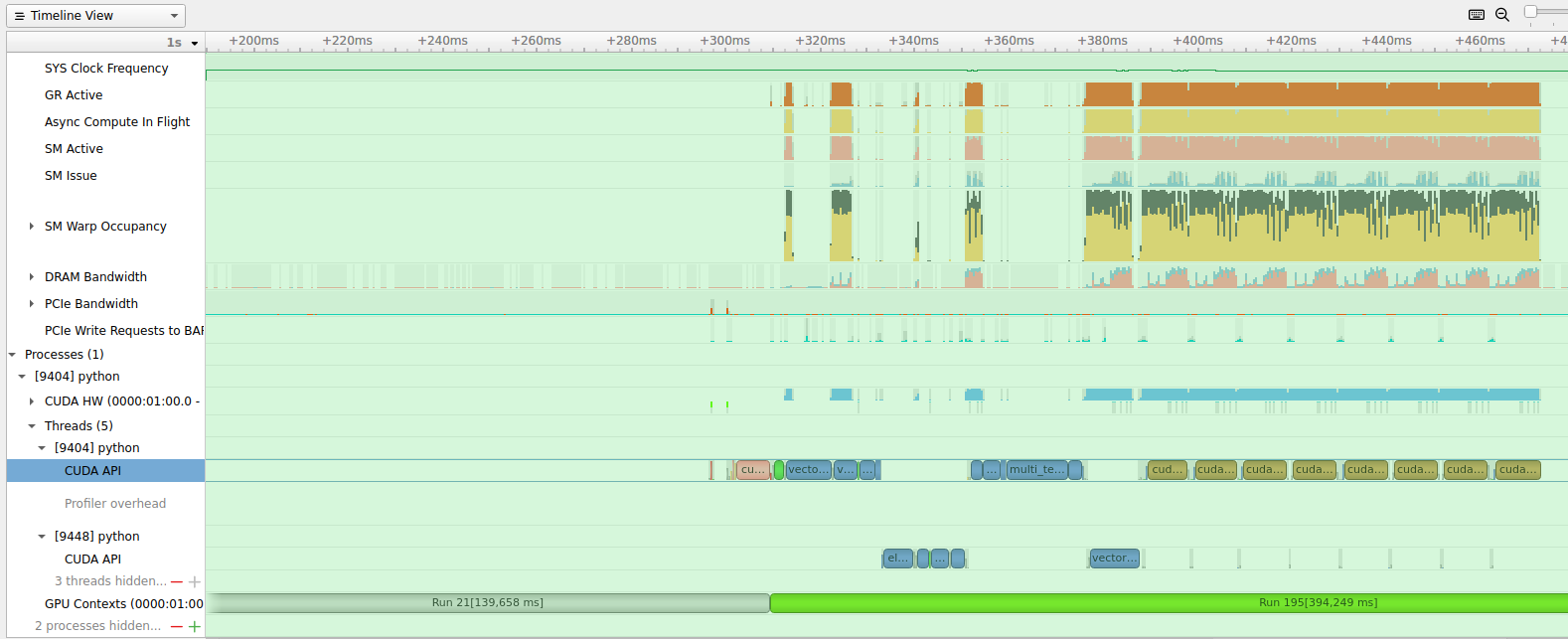
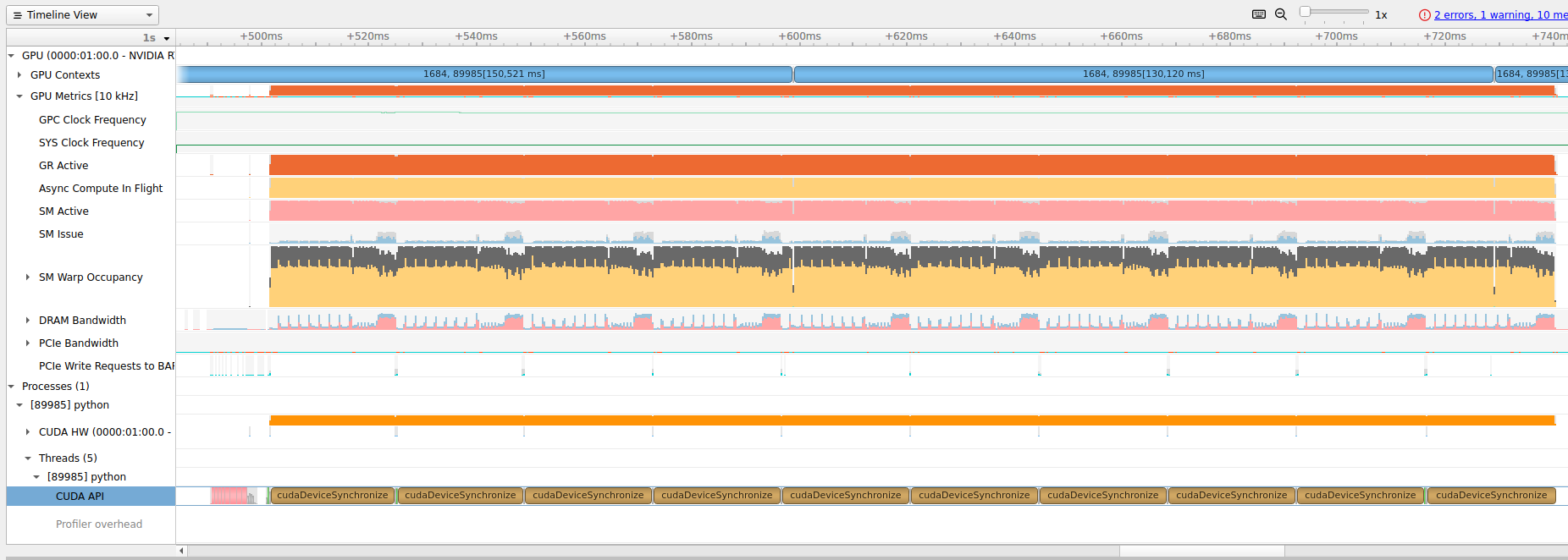
Running with on CPU, this results in iteration runtime reduction from 0.1998 → 0.1383. This is close to the expected (as ~33% is still coming from the first forward pass, subsequent forward pass and backward pass should take ~30% of the whole iteration, hence in total ~0.63).
But turning to GPU, I see no noticeable runtime reduction.
import torch
import torch.nn as nn
import time
from torch.autograd import profiler
from functools import wraps
from typing import Callable
def HSMWrap(fn):
@wraps(fn)
def wrapper(x):
return HSM.apply(x, fn)
return wrapper
class HSM(torch.autograd.Function):
@staticmethod
def forward(ctx, x, original_fun):
ctx.x = x
ctx.original_fun = original_fun
with torch.no_grad(): # first we do the forward pass in inference mode
y = original_fun(x)
y.requires_grad_(True)
return y
@staticmethod
def backward(ctx, dy):
B = ctx.x.shape[:-1].numel() # batch size
G = dy.norm(dim=-1)
b = int(B*0.3) # draw 30% of the samples proportionally to their output gradient norm
idx = torch.multinomial(G, b) # draw the hard indices
with torch.set_grad_enabled(True):
y = ctx.original_fun(ctx.x[idx]) # second forward pass, now building the computational graph
torch.autograd.backward((y), (dy[idx]))
return None, None
# Define a simple MLP model
class SimpleMLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size, num_hidden=3):
super(SimpleMLP, self).__init__()
# Add hidden layers
self.layers = nn.ModuleList()
self.layers.append(nn.Linear(input_size, hidden_size))
self.layers.append(nn.ReLU())
for _ in range(1, num_hidden):
self.layers.append(nn.Linear(hidden_size, hidden_size))
self.layers.append(nn.ReLU())
self.layers.append(nn.Linear(hidden_size, output_size))
def forward(self, x):
for layer in self.layers:
x = layer(x)
return x
# Create an instance of your MLP model and move it to CUDA device
input_size = 3
output_size = 3
hidden_size = 64 # Example hidden layer size
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = SimpleMLP(input_size, hidden_size, output_size, num_hidden=3).to(device)
# Wrap the forward method with HSMDecorator
model.forward = HSMWrap(model.forward)
# Now, prepare synthetic data and perform training iterations
num_iterations = 1000
batch_size = 2**18
# Define a loss function (e.g., MSE) and optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Generate random input data and labels on CUDA device
inputs = torch.randn(batch_size, input_size).to(device)
inputs.requires_grad_(True)
labels = torch.randn(batch_size, output_size).to(device)
# Start profiling
with profiler.profile(record_shapes=True, use_cuda=True) as prof:
for i in range(num_iterations):
# prof.step() # Need to call this at each step to notify profiler of steps' boundary.
iter_start = time.time()
# Generate random input data and labels on CUDA device
# Zero the gradients
optimizer.zero_grad()
# Forward pass
with torch.profiler.record_function('forward'):
outputs = model(inputs)
# Compute loss
loss = criterion(outputs, labels)
# Backward pass
with torch.profiler.record_function('backward'):
loss.backward()
# Update weights
optimizer.step()
torch.cuda.synchronize()
print(f"\rIteration: [{i + 1}/{num_iterations}], Time: {(time.time()-iter_start):.4}", end="")
# # Print and analyze profiling results
print("")
print(prof.key_averages().table(sort_by="cuda_time_total", row_limit=10))
Without wrapping (so commenting out model.forward = HSMWrap(model.forward)) this results in print:
Iteration: [1000/1000], Time: 0.01181
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
forward 0.75% 95.759ms 3.08% 390.711ms 390.711us 27.806ms 0.17% 6.477s 6.477ms 1000
aten::linear 0.43% 54.461ms 1.80% 228.364ms 57.091us 24.601ms 0.15% 5.549s 1.387ms 4000
aten::addmm 0.68% 86.382ms 0.86% 109.654ms 27.413us 5.481s 32.86% 5.481s 1.370ms 4000
backward 10.37% 1.315s 10.59% 1.344s 1.344ms 4.859s 29.13% 4.874s 4.874ms 1000
autograd::engine::evaluate_function: AddmmBackward0 0.64% 80.717ms 3.64% 461.371ms 115.343us 25.974ms 0.16% 3.119s 779.675us 4000
AddmmBackward0 0.87% 110.012ms 2.57% 325.843ms 81.461us 46.677ms 0.28% 2.472s 618.055us 4000
aten::mm 0.58% 73.359ms 0.72% 91.554ms 11.444us 2.348s 14.08% 2.348s 293.555us 8000
autograd::engine::evaluate_function: ReluBackward0 0.16% 20.259ms 0.48% 60.591ms 20.197us 8.433ms 0.05% 1.458s 485.893us 3000
ReluBackward0 0.14% 17.769ms 0.32% 40.332ms 13.444us 8.248ms 0.05% 1.449s 483.082us 3000
aten::threshold_backward 0.12% 15.319ms 0.18% 22.557ms 7.519us 1.441s 8.64% 1.441s 480.332us 3000
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 12.687s
Self CUDA time total: 16.682s
With wrapping on:
Iteration: [1000/1000], Time: 0.01107
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Name Self CPU % Self CPU CPU total % CPU total CPU time avg Self CUDA Self CUDA % CUDA total CUDA time avg # of Calls
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
aten::linear 0.53% 98.896ms 2.12% 392.019ms 49.002us 42.655ms 0.28% 6.494s 811.807us 8000
aten::addmm 0.81% 150.811ms 0.98% 181.945ms 22.743us 6.384s 41.51% 6.384s 798.027us 8000
forward 0.15% 28.466ms 2.08% 384.580ms 384.580us 13.552ms 0.09% 5.933s 5.933ms 1000
HSM 0.52% 95.585ms 1.92% 356.114ms 356.114us 25.659ms 0.17% 5.919s 5.919ms 1000
backward 43.09% 7.984s 43.32% 8.026s 8.026ms 4.485s 29.16% 4.500s 4.500ms 1000
autograd::engine::evaluate_function: HSMBackward 0.06% 10.196ms 40.71% 7.543s 7.543ms 2.544ms 0.02% 4.417s 4.417ms 1000
HSMBackward 1.98% 366.338ms 40.66% 7.533s 7.533ms 69.772ms 0.45% 4.415s 4.415ms 1000
aten::relu 0.27% 50.232ms 0.58% 106.960ms 17.827us 15.755ms 0.10% 1.180s 196.715us 6000
aten::clamp_min 0.19% 35.375ms 0.31% 56.703ms 9.450us 1.165s 7.57% 1.165s 194.089us 6000
autograd::engine::evaluate_function: AddmmBackward0 0.44% 81.859ms 2.39% 443.330ms 110.832us 24.625ms 0.16% 1.078s 269.508us 4000
------------------------------------------------------- ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------ ------------
Self CPU time total: 18.529s
Self CUDA time total: 15.381s