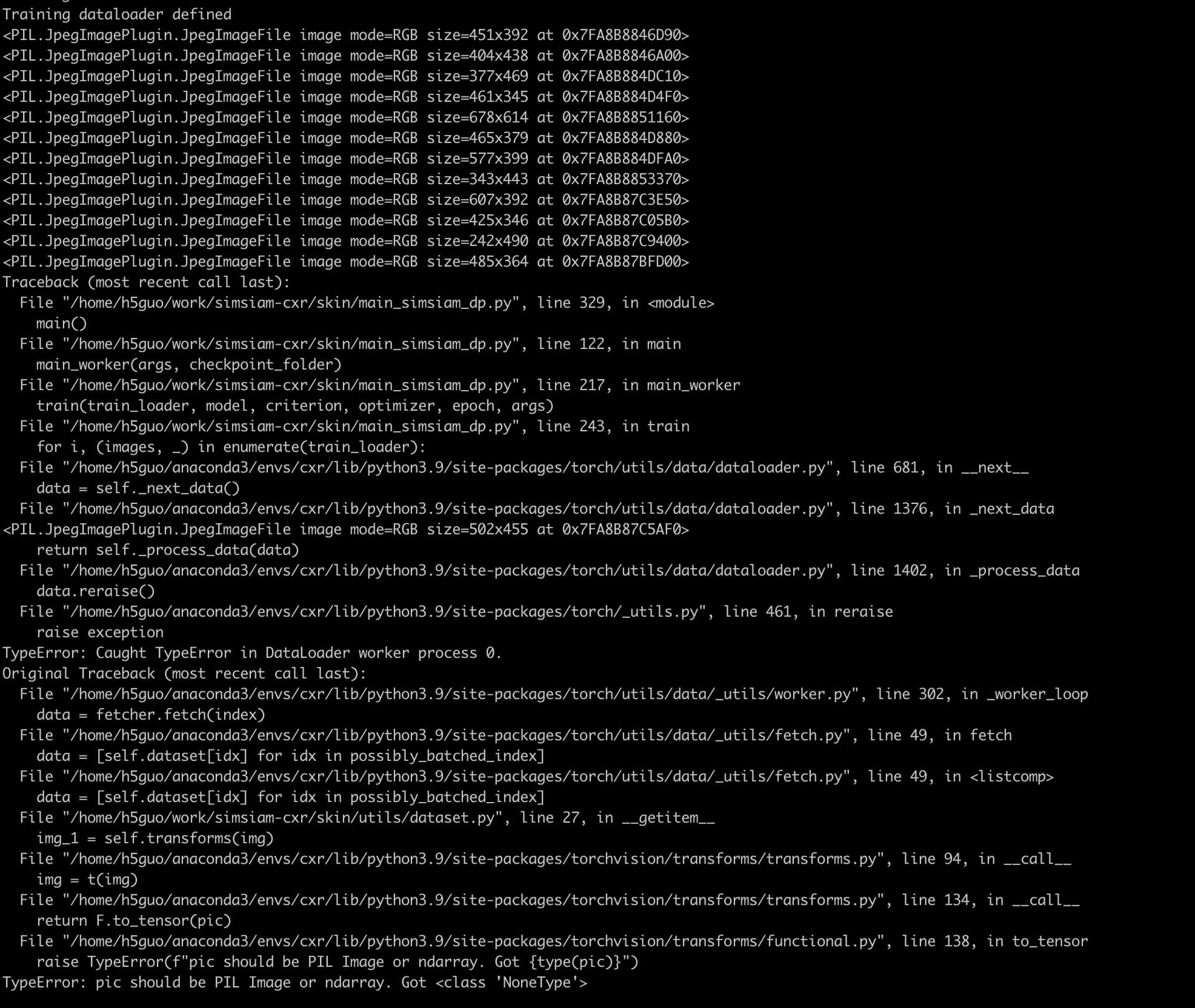
I’m trying to use a custom unlabeled dataset for self-supervised training and I got “TypeError: pic should be PIL Image or ndarray. Got <class ‘NoneType’>”. I have double checked the image files in the directory and it is seems that no image is missing. I have attached relevant code snippet below.
This is the definition of my dataset
from torch.utils.data import Dataset
from PIL import Image
import torchvision.transforms as transforms
import os
class UnlabelDataset(Dataset):
def __init__(self, data_path=None, transforms=None):
self.im_list = os.listdir(data_path)
self.transforms = transforms
self.data_path = data_path
# print(self.im_list)
# for image in self.im_list:
# if not os.path.isfile(os.path.join(self.data_path, image)):
# print(f"{os.path.join(self.data_path, image)} not present!")
# exit()
def __getitem__(self, index):
# load image and return an image pair as indicated in SimSiam
if self.data_path is not None:
img_path = os.path.join(self.data_path, self.im_list[index])
img = Image.open(img_path)
# print(img)
else:
img = Image.open(self.im_list[index])
img_1 = self.transforms(img)
img_2 = self.transforms(img)
return [img_1, img_2]
def __len__(self):
return len(self.im_list)
This is the definition of train set and train loader
traindir = args.train_data
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
augmentation = [
# transforms.RandomResizedCrop(224, scale=(0.2, 1.)),
transforms.Resize(224),
transforms.RandomApply([
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1) # not strengthened
], p=0.8),
transforms.RandomGrayscale(p=0.2),
transforms.RandomApply([simsiam.loader.GaussianBlur([.1, 2.])], p=0.5),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize
]
train_dataset = UnlabelDataset(traindir, transforms.Compose(augmentation))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, num_workers=args.workers, pin_memory=True, drop_last=True)
for epoch in range(args.start_epoch, args.epochs):
adjust_learning_rate(optimizer, init_lr, epoch, args)
train(train_loader, model, criterion, optimizer, epoch, args)
Here is the train function.
def train(train_loader, model, criterion, optimizer, epoch, args):
batch_time = AverageMeter('Time', ':6.3f')
data_time = AverageMeter('Data', ':6.3f')
losses = AverageMeter('Loss', ':.4e')
progress = ProgressMeter(
len(train_loader),
[batch_time, data_time, losses],
prefix="Epoch: [{}]".format(epoch))
# switch to train mode
model.train()
end = time.time()
for i, (images, _) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
images[0] = images[0].cuda()
images[1] = images[1].cuda()
# loss from datadict
p1, p2, z1, z2 = model(x1=images[0], x2=images[1])
loss = -(criterion(p1, z2).mean() + criterion(p2, z1).mean()) * 0.5
losses.update(loss.item(), images[0].size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
progress.display(i)
i += 1
sys.stdout.flush()
And this is the error I received.