I think it might be useful for a lot of people to devise a roadmap of sorts when dealing with hdf5 files in combination with pytorch.
After digging deep into literally every thread on this board I draw the following conclusions that should be modified/extended as you see fit.
hdf5, even in version 1.10 does not support multiple process read, so that one has to find a solution to be able to use a worker number > 0 in the data loading process. But what is the best option here?
Load smaller datasets entirely from hdf5 to RAM prior to any training
Open the file once with a singleton of sorts within the getitem method as discussed
Use pandas tables, havent looked into it myself,
use zarr, I read about it, but also did not try it yet
in my experience, using a large hdf5 file with several large data sets inside, the GPU idles for most of the time until its utilization suddenly peaks up to ~80% before dropping below 5% again. This pattern repeats, as such, I cannot confirm your statement
There is no overhead from opening the hdf5 file and loading data is successfully covered with GPU execution . DataLoader’s __next__ operation (getting next batch) in main process takes below 1% of the profiling time and we have full utilisation of GTX1060!
I have 8 CPU cores and a Ti1080 with 11 GB, may I ask how many workers you use in the dataloading process?
Also: Have you experienced problems where data is corrupted/mixed up if read with multiple workers from hdf5 as described e.g. here?
To fully utilise 1060GTX I needed only 4 workers. However, I also use V100 card and 10 workers on that machine and I wan’t able to fully utilise this GPU neither using PyTorch nor Keras, so you may be right that there is need for some roadmap from more experienced people how to properly parallelise preprocessing and feed data into GPU. Do you have some useful resources?
do you also experience sudden drops of GPU utilization at the end of every epoch? it drops rapidly to 1% before increasing again to a solid 90% and I cannot find a remedy thus far.
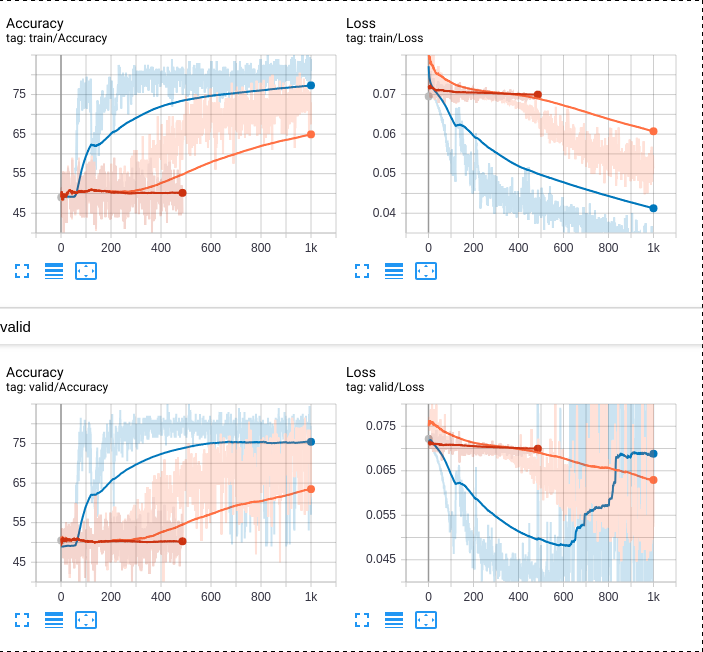
I am still at a loss as to how to get hdf5 working in a multiprocessing environment. I included several NaN checks in my scripts to exclude suspected corruption of data but I am still experiencing inconsistent behaviour across multiple parallel training runs. To be precise. I am working on a GPU cluster with four Ti1080s inside virtualenvs and all I changed from run to run is the number of workers, ranging from 0 to 4 and 8, up to 16. Since I suspected that data might be corrupted if read from the same files although swmr is enabled, I used distinct hdf5 files for all four parallel runs. To be clear: I only ever read data, I do not write any. Still strange behaviour remains present as can be clearly seen by looking at the images.
I read in this stack overflow post that although data is read from different files it still may be corrupted due to the way, the hdf5 lib handles access system-wide. Having said that, I thought that this issue would be long gone since that post is dating back to 2016 but apparently it is still prevailing. Concretely I am wondering about the following
Is this issue in some form related to multiprocessing, i.e. number of workers I use in my training?
If I run the same script on different GPUs each pulling its own data from SSD, are the dataloaders in python somehow intertwined, i.e. interfering with each other or completely unrelated?
I read in the stack-overflow post above that there apparently used to be differences in the build of h5py, if used in a conda environment as opposed to an python virtualenv
If so, how can I make sure I use the h5py thread-safe build within my virtualenv?
do I have to write the respective hdf5 file with swmr mode as well, if I intend to read them with swmr later on?
I hope someone has the experience/knowledge to help me with my issue