I am Unable to match the height and width of image, mask.
Here is my code can anyone help me with this
!pip install segmentation-models-pytorch
!pip install -U git+https://github.com/albumentations-team/albumentations
!pip install --upgrade opencv-contrib-python
!git clone https://github.com/parth1620/Human-Segmentation-Dataset-master.git
import sys
sys.path.append('/content/Human-Segmentation-Dataset-master')
import torch
import cv2
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tqdm import tqdm
import helper
CSV_FILE = '/content/Human-Segmentation-Dataset-master/train.csv'
DATA_DIR = '/content/'
DEVICE = 'cuda'
EPOCHS = 25
LR = 0.003
IMG_SIZE = 320
BATCH_SIZE = 16
ENCODER = 'timm-efficientnet-b0'
WEIGHT = 'imagenet'
train_df, valid_df = train_test_split(df, test_size = 0.2, random_state = 42)
import albumentations as A
def get_train_augs():
return A.Compose([
A.Resize(IMG_SIZE, IMG_SIZE),
A.HorizontalFlip(p = 0.5),
A.VerticalFlip(p = 0.5),
])
def get_valid_augs():
return A.Compose([
A.Resize(IMG_SIZE, IMG_SIZE),
])
from torch.utils.data import Dataset
class SegmentationDataset(Dataset):
def __init__(self, df, augmentations):
self.df = df
self.augmentations = augmentations
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
row = self.df.iloc[idx]
image_path = row.images
mask_path = row.masks
image = cv2.imread(image_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
mask = cv2.imread(mask_path, cv2.IMREAD_GRAYSCALE)
mask = np.expand_dims(mask, axis = -1)
if self.augmentations:
data = self.augmentations(image = image, mask = mask)
image = data['image']
mask = data['mask']
image = np.transpose(image, (2,0,1)).astype(np.float32)
mask = np.transpose(mask, (2,0,1)).astype(np.float32)
image = torch.Tensor(image) / 255.0
mask = torch.round(torch.Tensor(mask) / 255.0)
return image, mask
trainset = SegmentationDataset(train_df, get_train_augs())
validset = SegmentationDataset(valid_df, get_valid_augs())
print(f"Size of Trainset : {len(trainset)}")
print(f"Size of Validset : {len(validset)}")
idx = 3
image, mask = trainset[idx]
helper.show_image(image, mask)
from torch.utils.data import DataLoader
trainloader = DataLoader(trainset, batch_size=BATCH_SIZE, shuffle = True)
validloader = DataLoader(validset, batch_size=BATCH_SIZE)
print(f"Total no. of batches in trainloader : {len(trainloader)}")
print(f"Total no. of batches in validloader : {len(validloader)}")
for image, mask in trainloader:
break
print(f"One batch images shape : {image.shape}")
print(f"One batch masks shape : {mask.shape}")
I am facing the error in the last for loop, the error is
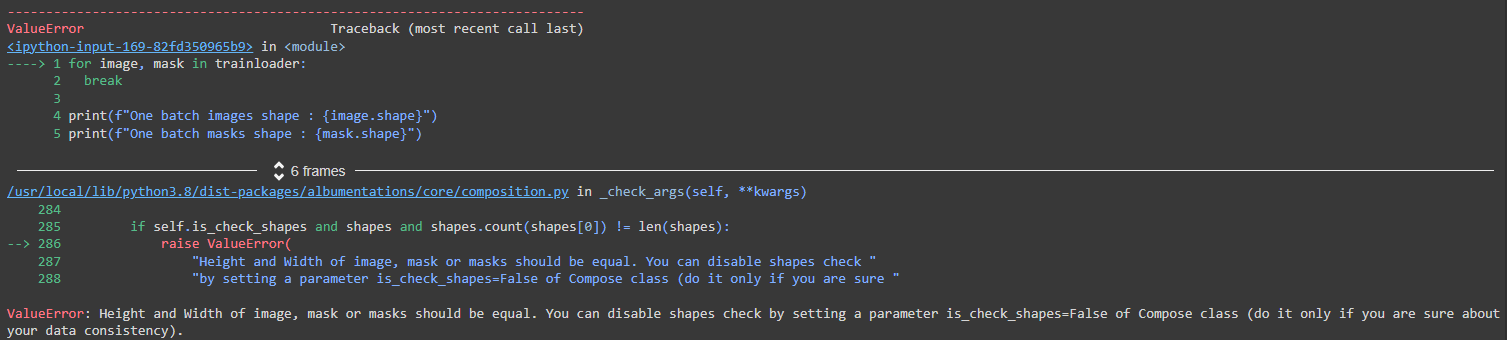
Can anyone please help me with this