Hello everyone, I am trying to implement the following loss function:
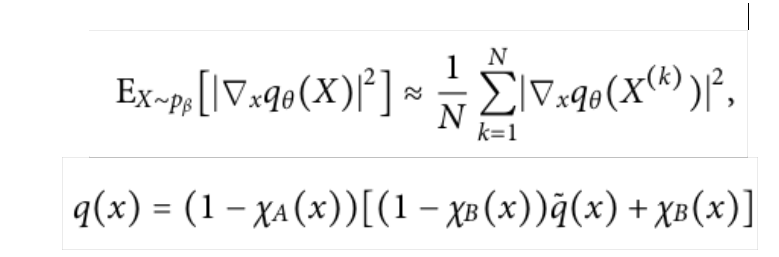
I have to perform a SGD to parameterize qθ(x), and q̃θ(x) is the parametrized part of the function.
So far I’ve come up with something like this:
def objective(p, output):
x,y = p
a = minA
b = minB
r = 0.1
XA = 1/2 -1/2 * torch.tanh(100*((x - a[0])**2 + (y - a[1])**2 - (r + 0.02)**2))
XB = 1/2 -1/2 * torch.tanh(100*((x - b[0])**2 + (y - b[1])**2 - (r + 0.02)**2))
q = (1-XA)*((1-XB)* output - (XB))
print("In obective function, q is", q)
output_grad, = torch.autograd.grad(q, (x,y), retain_graph=True, create_graph=True)
q = output_grad**2
return q
This problem can be viewed as an unsupervised minimization problem. I am using as training data points that I’ve indepentely sampled from a distribution.
The training is:
for e in range(epochs) :
for configuration in total:
# Training pass
optimizer.zero_grad()
#output is q~
output = model(configuration)
#loss is the objective function we defined
loss = objective(configuration, output)
loss.backward()
optimizer.step()
In particular, I get the error: “RuntimeError: One of the differentiated Tensors does not require grad”.
Thank you to anyone who will help me.