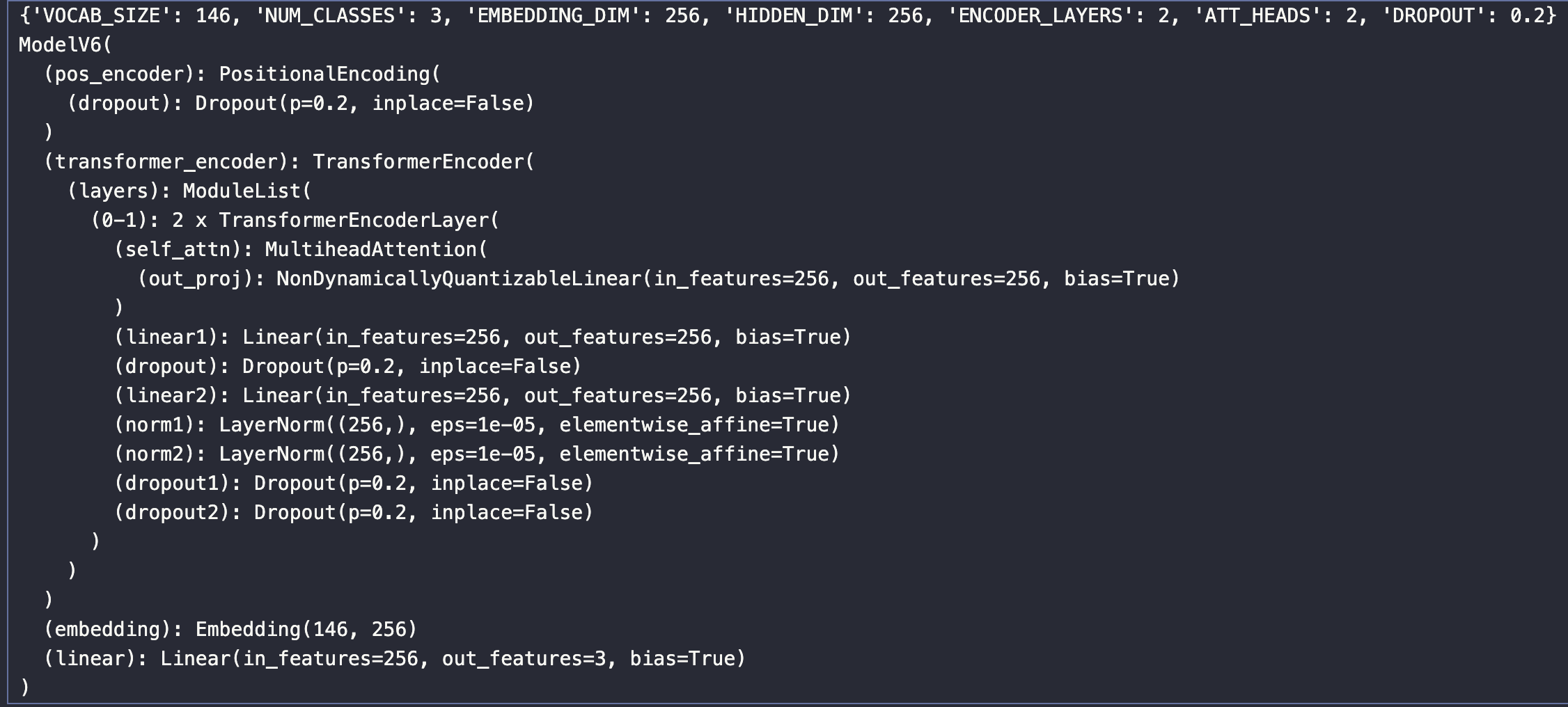
Hi there,
![]() I’m very much beginning my journey into PyTorch, and thought I’d reach out for advice and suggested improvements.
I’m very much beginning my journey into PyTorch, and thought I’d reach out for advice and suggested improvements.
I’m playing with a model that predicts football (soccer) matches. Raw data is in this CSV format:
season,date,home_team,away_team,home_goals,away_goals,result
2019,2019-08-09,Liverpool,Norwich,4,1,H
For the ‘result’ column:
H: Home team won
A: Away team won
D: The match was a draw
I can feed my model a home and away team (which are converted into a list of unique ints), and have it predict the result of a match in ints (H: 2 / A: 1 / D: 0).
But after training for a while it’s not that effective, I can see the loss going down to about 0.49, but I can’t seem to reduce it more than that.
Is this just the nature of sports data, or am I introducing any bad practices in my code? Any tips and guidance on this kind of project would be greatly appreciated. ![]()
import matplotlib.pyplot as plt
import numpy as np
import pandas
import torch
from torch import nn
from sklearn.model_selection import train_test_split
def get_data():
csv = pandas.read_csv('./data.csv')
data = csv.drop(
columns=['season', 'home_goals', 'away_goals'])
return data
def get_teams():
# Combine home and away team names, get unique cases + optionally sort
teams_unique = pandas.concat(
[data['home_team'], data['away_team']]).unique()
teams_sorted = np.sort(teams_unique)
teams = dict(zip(teams_sorted, range(len(teams_sorted))))
return teams
# Build dictionary
data = get_data()
teams = get_teams()
def get_team(team_str="Arsenal"):
# Get one hot encoded teams function, for use now and later when predicting
return teams[team_str]
# Features / teams as ints
data_features = []
for r in data.itertuples():
data_features.append([get_team(r.home_team), get_team(r.away_team)])
for r in data_features[:10]:
print(list(teams.keys())[r[0]], "vs", list(teams.keys())[r[1]])
# Scores
data_scores = []
for r in data[["result"]].itertuples():
result = r.result
res = 0
if result == "H":
res = 2
elif result == "A":
res = 1
else:
res = 0
data_scores.append(res)
# Split the data into training and testing sets
RANDOM_SEED = 42
X = torch.tensor(data_features, dtype=torch.float32)
y = torch.tensor(data_scores, dtype=torch.int64)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=RANDOM_SEED)
print(
f"X_train: {X_train.shape}: {X_train.dtype} | y_train: {y_train.shape}: {y_train.dtype}")
print(
f"X_test: {X_test.shape}: {X_test.dtype} | y_test: {y_test.shape}: {y_test.dtype}")
# Build the model
class ModelV1(nn.Module):
def __init__(self, INPUT_FEATURES=2, OUTPUT_FEATURES=2, HIDDEN_UNITS=8):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(in_features=INPUT_FEATURES,
out_features=HIDDEN_UNITS),
nn.Sigmoid(),
nn.Linear(in_features=HIDDEN_UNITS, out_features=HIDDEN_UNITS),
nn.Sigmoid(),
nn.Linear(in_features=HIDDEN_UNITS,
out_features=OUTPUT_FEATURES)
)
def forward(self, x):
return self.layers(x)
INPUT_FEATURES = X_train.shape[1]
HIDDEN_UNITS = len(teams) * 4
OUTPUT_FEATURES = 4
model = ModelV1(INPUT_FEATURES, OUTPUT_FEATURES, HIDDEN_UNITS)
# Loss
loss_fn = nn.CrossEntropyLoss()
# Optimizer
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# Accuracy
def accuracy_fn(outputs, targets):
correct = torch.sum(outputs == targets).item()
acc = (correct/len(outputs)) * 100
return acc
# Prepare
torch.manual_seed(RANDOM_SEED)
torch.backends.mps.manual_seed = RANDOM_SEED
# Set no of epochs
EPOCHS = 1000
print_steps = round(EPOCHS / 100)
losses = []
for epoch in range(EPOCHS):
model.train()
y_logits = model(X_train)
outputs = torch.softmax(y_logits, dim=0).argmax(dim=1)
loss = loss_fn(y_logits, y_train)
acc = accuracy_fn(outputs, y_train)
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
losses.append(loss.item())
if epoch % print_steps == 0:
print(f"Epoch: {epoch+1}/{EPOCHS} | Loss: {loss:.5f}")
with torch.inference_mode():
# Forward pass
test_logits = model(X_test)
outputs = torch.softmax(test_logits, dim=1).argmax(dim=1)
# Calculate test loss / acc
test_loss = loss_fn(test_logits, y_test)
test_acc = accuracy_fn(outputs, y_test)
# Compare results
print_steps = round(len(outputs) / 10)
correct = 0
for i, o in enumerate(outputs):
is_correct = y_test[i].item() == o.item()
icon = "✅" if is_correct else "❌"
correct += 1 if is_correct else 0
if i % print_steps == 0:
print(
f"{icon} Actual: {y_test[i].item():.2f} | Predicted: {o.item():.2f}")
print("-" * 30)
print(f"Correct: {correct} / {len(outputs)}")
print(f"Accuracy: {correct/len(outputs)*100:.2f}%")
# Plot training and test losses
plt.plot(range(EPOCHS), losses, label="Test Loss")
plt.legend(prop={'size': 12})
plt.show()