mark_eu
March 19, 2022, 11:04pm
1
Hi,
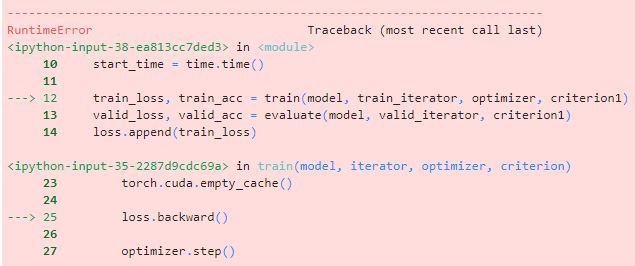
I need help. I have 32Gb of GPU and facing the problem of “Cuda out of memory.”
import gc
def train(model, iterator, optimizer, criterion):
epoch_loss = 0.0
epoch_acc = 0.0
model.train()
for batch in iterator:
optimizer.zero_grad()
predictions = model(batch.posts)
loss = criterion(predictions, batch.type_numeric.long().to(device))
acc = categorical_accuracy(predictions, batch.type_numeric.long().to(device))
loss.backward()
optimizer.step()
epoch_loss += loss.item()
epoch_acc += acc.item()
#####################
#the following part really slows the code execution
del predictions
del loss
del acc
del batch
gc.collect()
torch.cuda.empty_cache()
#####################
return epoch_loss / len(iterator), epoch_acc / len(iterator)
and also, I lowered the batch size to have small values:
train_batch_size = 4
valid_batch_size = 4
test_batch_size = 4
but still, I get the error Cuda out of memory:
My task is an NLP multiclass classification task on a dataset that has, after preprocessing, 1 Gb. I tried to reduce MAX_VOCAB_SIZE to 300. I use the CNN model with the parameters:
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 300
N_FILTERS = 100
FILTER_SIZES = [2,3,4]
OUTPUT_DIM = len(LABEL.vocab)
DROPOUT = 0.2
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token]
model = CNN(INPUT_DIM, EMBEDDING_DIM, N_FILTERS, FILTER_SIZES, OUTPUT_DIM, DROPOUT, PAD_IDX)
optimizer = optim.Adam(model.parameters())
criterion1 = nn.CrossEntropyLoss()
model = model.to(device)
criterion1 = criterion1.to(device)
Could you please help me with this - my deadline is approaching, and I have no other ideas on how to solve this issue.
Thank you
eqy
March 20, 2022, 12:50am
2
It’s a bit difficult to pinpoint this without more context on the model (e.g., how many parameters, layers, etc?) and is the OOM happening on the first iteration or after many iterations due to gradually increasing memory consumption?
If it is happening in the first few iterations you might want to check if the model size itself needs to be reduced, otherwise it might be worthwhile to see which operation is gradually increasing the total memory consumed over many iterations (you can check this by removing operations until the memory used stops increasing).
mark_eu
March 20, 2022, 10:10am
3
@eqy Thank you!
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0)
embedded = self.embedding(text)
embedded = embedded.unsqueeze(1)
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
cat = self.dropout(torch.cat(pooled, dim = 1))
return self.fc(cat)
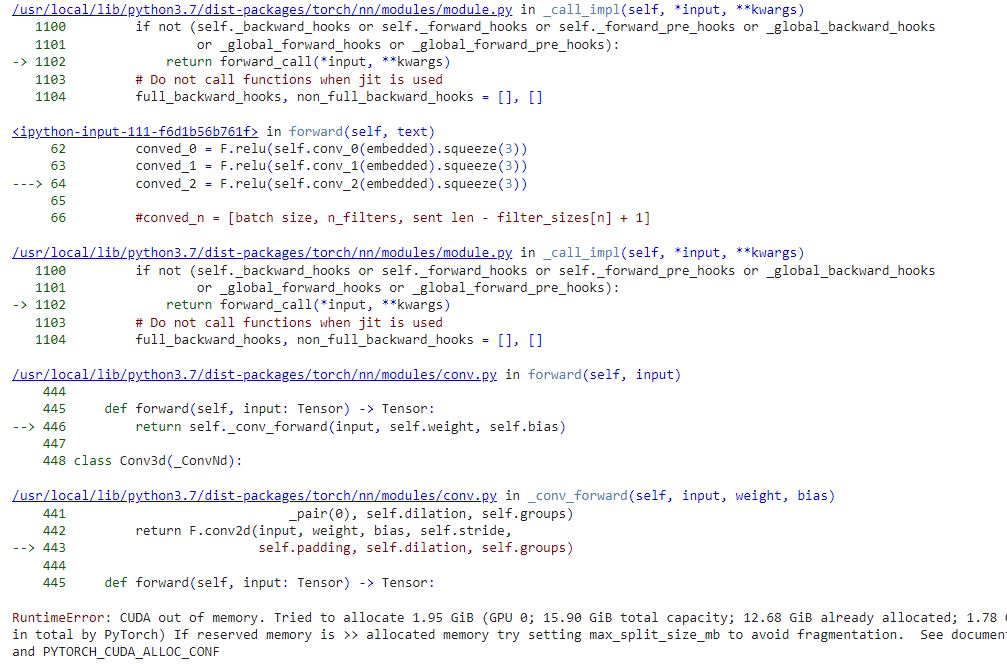
The model has 365,716 trainable parameters (in a ‘reduced’ version of MAX_VOCAB_SIZE = 300 instead of 25000 and batch sizes of 4, instead of 256/64/64). The OOM happens on the first iteration.
Do you have any suggestions for solving this problem? I also hope that @ptrblck and @albanD could give some advice(s). The problem does not exist with the same model on the small dataset (70MB)
mark_eu
March 22, 2022, 11:56am
4
It seems to me that the problem appears in :conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs
Also, for text vocabulary I use:
TEXT.build_vocab(train_ds,
min_freq = 3,
max_size = MAX_VOCAB_SIZE,
vectors = 'fasttext.en.300d',
unk_init = torch.Tensor.normal_
)
You are currently storing all activation outputs of self.convs in the conved list and are then applying the pooling on each of them.
mark_eu
March 24, 2022, 10:58pm
6
Thank you, @ptrblck , for your advice.
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
'''
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
'''
self.conv_0 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[0], embedding_dim))
self.conv_1 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[1], embedding_dim))
self.conv_2 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[2], embedding_dim))
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0)
embedded = self.embedding(text)
embedded = embedded.unsqueeze(1)
conved_0 = F.relu(self.conv_0(embedded).squeeze(3))
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
'''
conved_n = [batch size, n_filters, sent len - filter_sizes[n] + 1]
'''
pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
'''
pooled_n = [batch size, n_filters]
'''
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim = 1))
return self.fc(cat)
However, I still get CUDA out of memory error. Do you have any other suggestions?
There wouldn’t be any difference in your code as you are still storing all intermediate activations.
pooled_0 = F.max_pool1d(F.relu(self.conv_0(embedded).squeeze(3)))
mark_eu
March 25, 2022, 9:49am
8
Thank you, @ptrblck , for additional help.
import torch.nn as nn
import torch.nn.functional as F
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
'''
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
'''
self.conv_0 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[0], embedding_dim))
self.conv_1 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[1], embedding_dim))
self.conv_2 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[2], embedding_dim))
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0)
embedded = self.embedding(text)
embedded = embedded.unsqueeze(1)
conved_0 = F.relu(self.conv_0(embedded).squeeze(3))
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
'''
pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
'''
pooled_0 = F.max_pool1d(F.relu(self.conv_0(embedded).squeeze(3)))
pooled_1 = F.max_pool1d(F.relu(self.conv_1(embedded).squeeze(3)))
pooled_2 = F.max_pool1d(F.relu(self.conv_2(embedded).squeeze(3)))
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim = 1))
return self.fc(cat)
Now, I don’t know if I get Cuda out of memory since I get the error:
TypeError: _max_pool1d() missing 1 required positional argument: 'kernel_size'
Do you have a suggestion on how to solve it?
Thank you
The F.max_pool1d operations are missing the kernel size and you are also unnecessarily computing and storing conved_X.
mark_eu
March 25, 2022, 6:31pm
10
Thank you, @ptrblck ,
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim,
dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, pad_idx)
'''
self.convs = nn.ModuleList([
nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (fs, embedding_dim))
for fs in filter_sizes
])
'''
self.conv_0 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[0], embedding_dim))
self.conv_1 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[1], embedding_dim))
self.conv_2 = nn.Conv2d(in_channels = 1,
out_channels = n_filters,
kernel_size = (filter_sizes[2], embedding_dim))
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0)
embedded = self.embedding(text)
embedded = embedded.unsqueeze(1)
conved_0 = F.relu(self.conv_0(embedded).squeeze(3))
conved_1 = F.relu(self.conv_1(embedded).squeeze(3))
conved_2 = F.relu(self.conv_2(embedded).squeeze(3))
pooled_0 = F.max_pool1d(conved_0, conved_0.shape[2]).squeeze(2)
pooled_1 = F.max_pool1d(conved_1, conved_1.shape[2]).squeeze(2)
pooled_2 = F.max_pool1d(conved_2, conved_2.shape[2]).squeeze(2)
cat = self.dropout(torch.cat((pooled_0, pooled_1, pooled_2), dim = 1))
return self.fc(cat)
I again get the error:
I lowered batches to 1, but that didn’t help. @ptrblck , do you have any idea what else I could do to solve this problem?
Thank you
mark_eu
March 28, 2022, 12:51pm
11
Does anyone have any additional idea on how to solve this issue? @ptrblck , do you have any further suggestions?
Thank you