Hello i am jimit! I am trying to build Convolutional Seq2Seq model which are describe here!
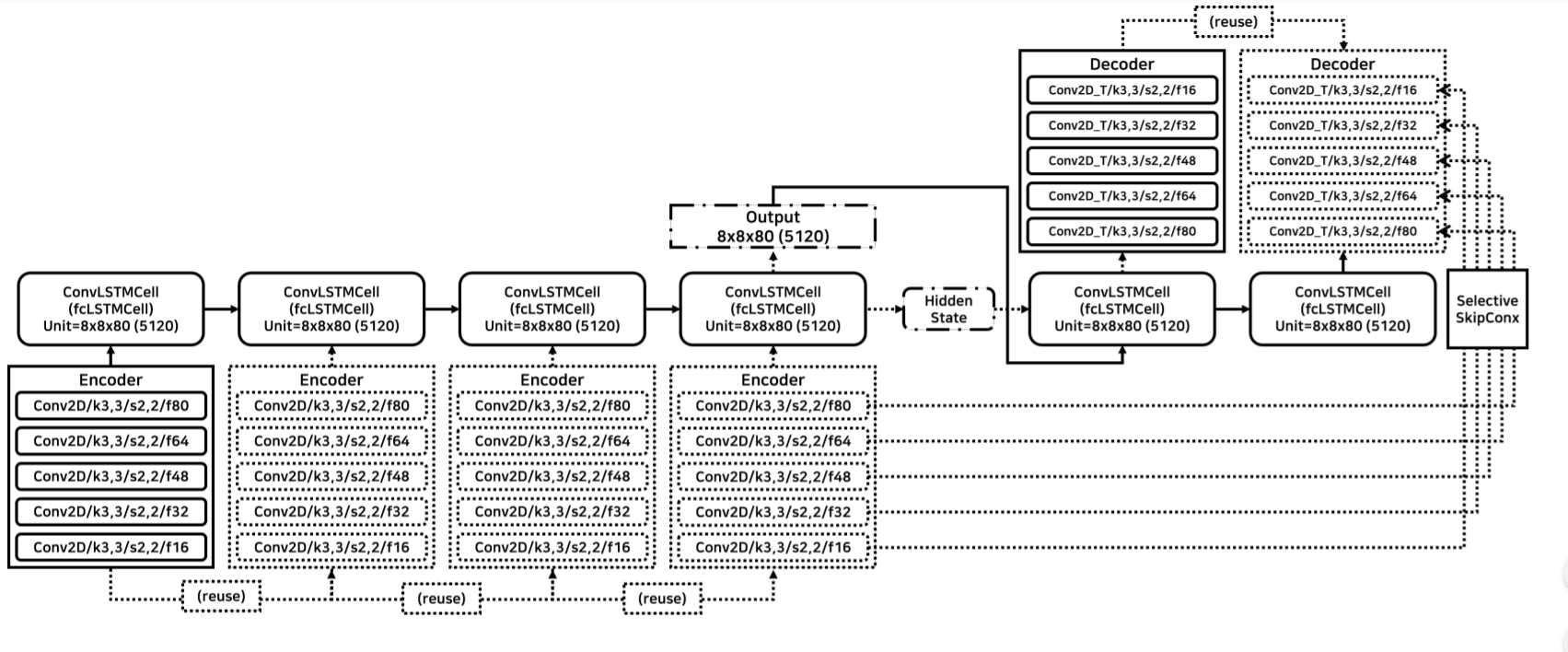
Here is the research paper -
Next Sequence Prediction of Satellite Images using a Convolutional Sequence-to-Sequence Network
I am give my full model code! please can you check my code ? Am I Correct implement my model?
import torch
from torch import nn
import torch.nn.functional as f
from torch.autograd import Variable
# Define some constants
KERNEL_SIZE = 3
PADDING = KERNEL_SIZE // 2
class ConvLSTMCell(nn.Module):
"""
Generate a convolutional LSTM cell
"""
def __init__(self, input_size, hidden_size):
super().__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.Gates = nn.Conv2d(input_size + hidden_size, 4 * hidden_size, KERNEL_SIZE, padding=PADDING)
def forward(self, input_, prev_state):
# get batch and spatial sizes
batch_size = input_.data.size()[0]
spatial_size = input_.data.size()[2:]
# generate empty prev_state, if None is provided
if prev_state is None:
state_size = [batch_size, self.hidden_size] + list(spatial_size)
print(state_size)
prev_state = (
Variable(torch.zeros(state_size)),
Variable(torch.zeros(state_size))
)
prev_hidden, prev_cell = prev_state
# data size is [batch, channel, height, width]
stacked_inputs = torch.cat((input_, prev_hidden), 1)
gates = self.Gates(stacked_inputs)
# chunk across channel dimension
in_gate, remember_gate, out_gate, cell_gate = gates.chunk(4, 1)
# apply sigmoid non linearity
in_gate = f.sigmoid(in_gate)
remember_gate = f.sigmoid(remember_gate)
out_gate = f.sigmoid(out_gate)
# apply tanh non linearity
cell_gate = f.tanh(cell_gate)
# compute current cell and hidden state
cell = (remember_gate * prev_cell) + (in_gate * cell_gate)
hidden = out_gate * f.tanh(cell)
return hidden, cell
input = Variable(torch.rand( 6, 3, 256, 256))
decoder_input = Variable(torch.rand( 6, 80, 8, 8))
conv = Conv2d(3, 16, kernel_size=(3, 3), stride=2, padding=1)(input)
conv1 = Conv2d(16, 32, kernel_size=(3, 3), stride=2, padding=1)(F.relu(conv))
conv2 = Conv2d(32, 48, kernel_size=(3, 3), stride=2, padding=1)(F.relu(conv1))
conv3 = Conv2d(48, 64, kernel_size=(3, 3), stride=2, padding=1)(F.relu(conv2))
conv4 = Conv2d(64, 80, kernel_size=(3, 3), stride=2, padding=1)(F.relu(conv3))
Encoder, prev_c,= ConvLSTMCell(80, 80)(F.relu(conv4), None)
states = (Encoder, prev_c)
decoder_cell = ConvLSTMCell(80, 80)
decoder, _ = decoder_cell(decoder_input, states)
layer = ConvTranspose2d(80, 80, kernel_size=(1, 1))(F.relu(decoder))
m = torch.cat([F.relu(layer), conv4], dim=1)
layer1 = ConvTranspose2d(160, 64, kernel_size=(2, 2), stride=2)(m)
m1 = torch.cat([F.relu(layer1), conv3], dim=1)
layer2 = ConvTranspose2d(128, 48, kernel_size=(2, 2), stride=2)(m1)
m2 = torch.cat([F.relu(layer2), conv2], dim=1)
layer3 = ConvTranspose2d(96, 32, kernel_size=(2, 2), stride=2)(m2)
m3 = torch.cat([F.relu(layer3), conv1], dim=1)
layer4 = ConvTranspose2d(64, 16, kernel_size=(2, 2), stride=2)(m3)
m4 = torch.cat([F.relu(layer4), conv], dim=1)
output = ConvTranspose2d(32, 3, kernel_size=(2, 2), stride=2)(m4)
can you correct my model? please?