I want to get the probabilities from the output of the model after testing it with one sample. I use this code to test:
for batch_idx, (x, y) in enumerate(dataloader): #comprised of one sample
x = Variable(x.cuda()) #sample of size 22761
y = Variable(y.cuda()) #label, which is 1
# forward pass
y_model = model(x)
print(torch.log(y_model))
And get the following output:
Variable containing:
0.0000 -16.9570
[torch.cuda.FloatTensor of size 1x2 (GPU 0)]
I don’t know what these values mean or why they are the same for every input. Could someone please explain what is happening?
I assume you’ve also used torch.log(y_model) during training, as nn.NLLLoss expects log-probabilities as input. If so, you might encounter some issues regarding the numerical stability. It’s usually better to call F.log_softmax on the output.
That being said, you are printing out the log-probabilities for both classes.
It seems your model gives class0 a very high probability (basically 100%) and a very low one to class1.
To see the probabilities, just remove the torch.log call on y_model.
If you test your model, you should call model.eval() on it to switch the behavior of some layers to evaluation.
In your case it doesn’t seem to be necessary as your model doesn’t have nn.BatchNorm or nn.Dropout layers.
Does your model output the same values for every sample in the test set?
How was your training accuracy? Do you have an imbalanced dataset, i.e. many samples of class0 and very few of class1?
Also, as another side node, Variables are deprecated since 0.4.0. You can now just use tensors directly.
If you want the volatile behavior, use with torch.no_grad(): for your eval loop.
Variable containing:
1.0000e+00 4.3219e-08
[torch.cuda.FloatTensor of size 1x2 (GPU 0)]
Something seems wrong here. The output is always the same for every sample. I am using Pytorch 3.0 to get the same results as a paper’s implementation I am following.
I have retrained the model with LogSoftMax and NLLLoss with the same parameters. when I use torch.exp(y_model) I get the following for a single sample:
Variable containing:
0.5180 0.4820
[torch.cuda.FloatTensor of size 1x2 (GPU 0)]
This means that the model is not sure which class the sample is? That output is also the same for a large test set. The training set is balanced with 19000 samples for both classes. I used code from another implementation to train the model, and it is very confusing, I might have also somehow trained this model incorrectly.
So after retraining with F.log_softmax your model outputs the new probabilities? How is your accuracy during training? Do you calculate the validation accuracy as well?
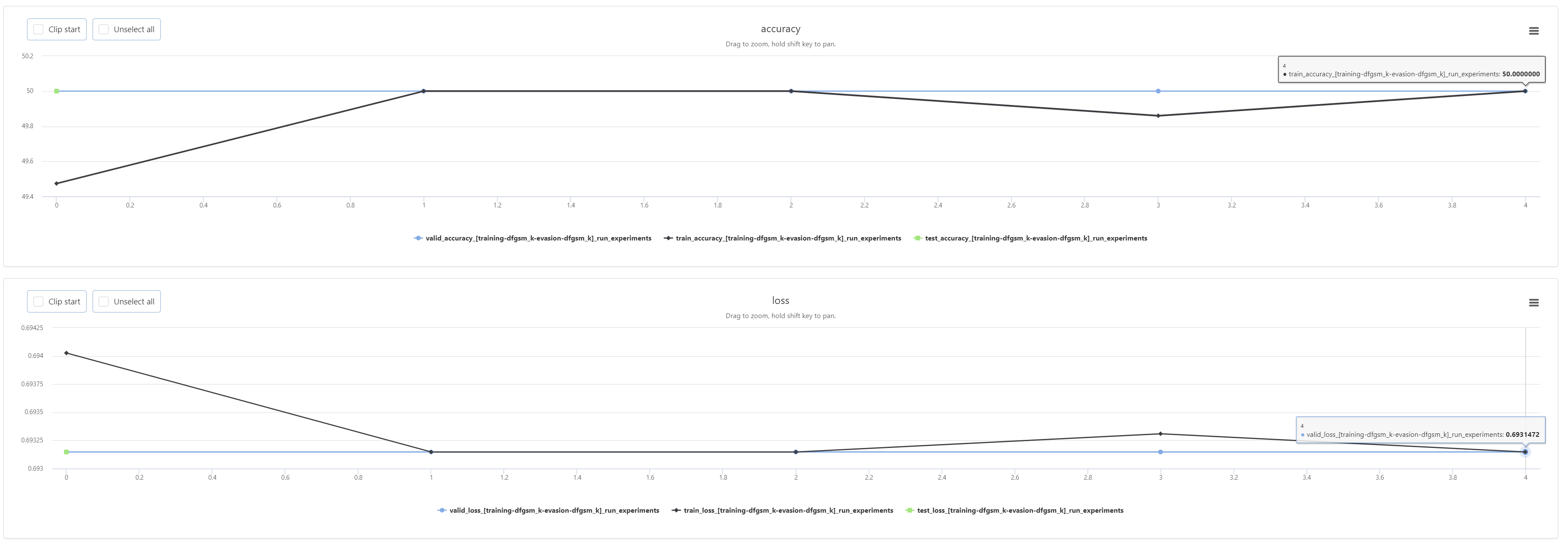
For some reason the model’s accuracy gets stuck at exactly 50%? Does this mean the model is being trained incorrectly? The model outputs 0.5 for all samples and classes.
Yes, your model doesn’t learn anything useful. It just outputs class0 for every sample. That’s also the reason you get the same predictions in your test set, as the training also fails.
Could you try to use a small sample of your training data and overfit your model on it?
If that’s not possible your architecture, hyperparameters etc. are not suitable for the task or you might have a bug somewhere in your training procedure.
I used 5 epochs to train the model whereas they used 300, does it matter? Even with just 5 I should still be seeing some results.
After debugging the code I see that the dataloader lists my malicious class (my two classes are “malicious” and “benign”) of my training dataloader as follows:
Is the timeout significant? I never noticed it before, and have no idea why its just for that class.
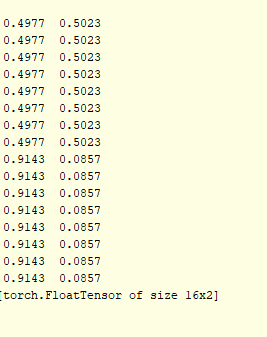
But everything still seems to work, The very first training batch of 8 samples of both classes gives this as output (after evaluated with torch.exp(y_model)):
Does this mean the samples do have some effect on the training? Still not sure what is going, however it looks like the model is getting all the data fed in correctly.
I tried to overfit the model on a small sample size but it still only outputs 50% accuracy. I have no idea what is going on.
With a small sample size and 20 epochs or a large sample size with 5 epochs the model doesn’t learn anything. I am using vectors comprised of 0’s and 1’s of size 22761.