Hi everyone, I’m new here and new to PyTorch overall, I am training a model to diacritize Arabic sentences (multilabel classification) and I used those classes below a basic self-attention transformer class and another one with a diacritization head on top
import torch
import torch.nn as nn
from torch.nn.modules.activation import MultiheadAttention
# This code is based on NAACL 2019 tutorial here https://tinyurl.com/NAACLTransfer
class Transformer(nn.Module):
'''
This class defines a basic self-attention transformer.
Args:
embed_dim (int): dimension of the embeddings used in the transformer attnetion blocks
hidden_dim (int): size of the fully connected layer connecting attention blocks
num_embeddings (int): vocbulary size
num_max_positions (int): maximum sequence length. used for positional embeddings
num_heads (int): number of attention heads used in Multihead Attention.
num_layer (int): number of layers. Each layer is an attention block and a fully connected layer.
dropout (float): dropout probability
causal (bool): whether to attend only to previous positions.
'''
def __init__(self, embed_dim, hidden_dim, num_embeddings, num_max_positions, num_heads, num_layers, dropout, causal):
super().__init__()
self.causal = causal
self.tokens_embeddings = nn.Embedding(num_embeddings, embed_dim)
self.position_embeddings = nn.Embedding(num_max_positions, embed_dim)
self.dropout = nn.Dropout(dropout)
self.attentions, self.feed_forwards = nn.ModuleList(), nn.ModuleList()
self.layer_norms_1, self.layer_norms_2 = nn.ModuleList(), nn.ModuleList()
for _ in range(num_layers):
self.attentions.append(MultiheadAttention(embed_dim, num_heads, dropout=dropout))
self.feed_forwards.append(nn.Sequential(nn.Linear(embed_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, embed_dim)))
self.layer_norms_1.append(nn.LayerNorm(embed_dim, eps=1e-12))
self.layer_norms_2.append(nn.LayerNorm(embed_dim, eps=1e-12))
def forward(self, x, padding_mask=None):
""" x has shape [seq length, batch], padding_mask has shape [batch, seq length] """
positions = torch.arange(len(x), device=x.device).unsqueeze(-1)
h = self.tokens_embeddings(x)
h = h + self.position_embeddings(positions).expand_as(h)
h = self.dropout(h)
attn_mask = None
if self.causal:
attn_mask = torch.full((len(x), len(x)), -float('Inf'), device=h.device, dtype=h.dtype)
attn_mask = torch.triu(attn_mask, diagonal=1)
for layer_norm_1, attention, layer_norm_2, feed_forward in zip(self.layer_norms_1, self.attentions,
self.layer_norms_2, self.feed_forwards):
h = layer_norm_1(h)
x, _ = attention(h, h, h, attn_mask=attn_mask, need_weights=False, key_padding_mask=padding_mask)
x = self.dropout(x)
h = x + h
h = layer_norm_2(h)
x = feed_forward(h)
x = self.dropout(x)
h = x + h
return h
import torch
import torch.nn as nn
class TransformerWithDiacritizationHead(nn.Module):
def __init__(self, config):
"""" Transformer with a diacritization head on top"""
super().__init__()
self.config = config
self.transformer = Transformer(config.embed_dim, config.hidden_dim, config.num_embeddings,
config.num_max_positions, config.num_heads, config.num_layers,
config.dropout, causal=config.causal)
self.diac_head = nn.Linear(config.embed_dim, config.num_diac_labels, bias=False)
def init_weights(self, module):
""" initialize weights - nn.MultiheadAttention is already initalized by PyTorch (xavier) """
if isinstance(module, (nn.Linear, nn.Embedding, nn.LayerNorm)):
module.weight.data.normal_(mean=0.0, std=self.config.initializer_range)
if isinstance(module, (nn.Linear, nn.LayerNorm)) and module.bias is not None:
module.bias.data.zero_()
def forward(self, x, labels=None, padding_mask=None, label_ignore_idx=-1):
""" x has shape [seq length, batch], padding_mask has shape [batch, seq length] """
hidden_states = self.transformer(x, padding_mask)
logits = self.diac_head(hidden_states) # seq_len x batch x num_labels
# print("len logits:{} - shape logits:{}".format(len(logits),logits.shape))
# print("len labels:{} - shape labels:{}".format(len(labels),labels.shape))
if labels is not None:
assert labels.size(0) == logits.size(0), "logits and labels dimension mismatch"
#shift_logits = logits[:-1] if self.transformer.causal else logits
#shift_labels = labels[1:] if self.transformer.causal else labels
loss_fct = nn.CrossEntropyLoss(ignore_index=label_ignore_idx)
loss = loss_fct(logits.view(-1, logits.size(-1)), labels.view(-1))
return logits, loss
return logits
the arguments for the model
from collections import namedtuple
Config = namedtuple('Config',
field_names="embed_dim, hidden_dim, num_max_positions, num_embeddings , num_heads, num_layers,"
"dropout,causal,num_diac_labels, initializer_range, batch_size, lr, max_norm, n_epochs, n_warmup,"
"mlm, gradient_accumulation_steps, device, log_dir, dataset_cache")
diac_args = Config( 512 , 512 , 256 , 38, 8 , 10 ,
0.1 ,False ,9, 0.02 , 64 , 0.0001, 5.0 ,1 , 1000 ,
False, 4, "cuda" if torch.cuda.is_available() else "cpu", "/kaggle/working/Arabic_DIACRITIZATION/trained_models" , "/kaggle/working/Arabic_DIACRITIZATION/dataset_cache.bin")
prepare training loop
from ignite.metrics import Accuracy
optimizer = torch.optim.Adam(diacritization_model.parameters(), lr=diac_args.lr)
# Training function and trainer
def update(engine, batch):
diacritization_model.train()
batch, labels = (t.to(diac_args.device) for t in batch)
inputs = batch.transpose(0, 1).contiguous() # to shape [seq length, batch]
labels = labels.transpose(0, 1).contiguous()
predicted_label, loss = diacritization_model(inputs, labels = labels, padding_mask=None,label_ignore_idx=-1)
loss = loss / diac_args.gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(diacritization_model.parameters(), diac_args.max_norm)
if engine.state.iteration % diac_args.gradient_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
return loss.item()
trainer = Engine(update)
# Evaluation function and evaluator (evaluator output is the input of the metrics)
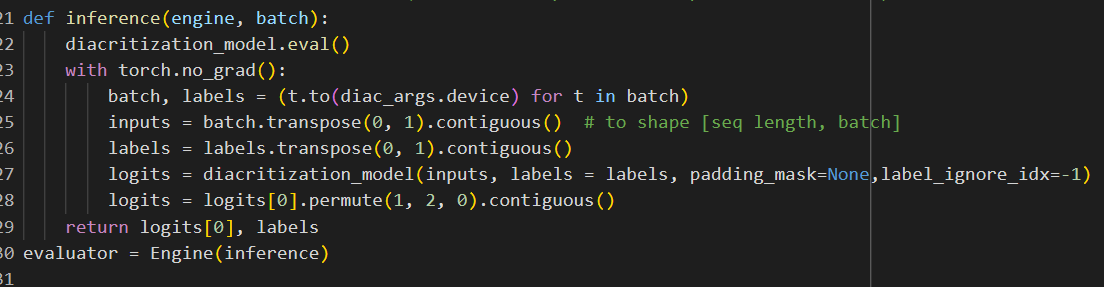
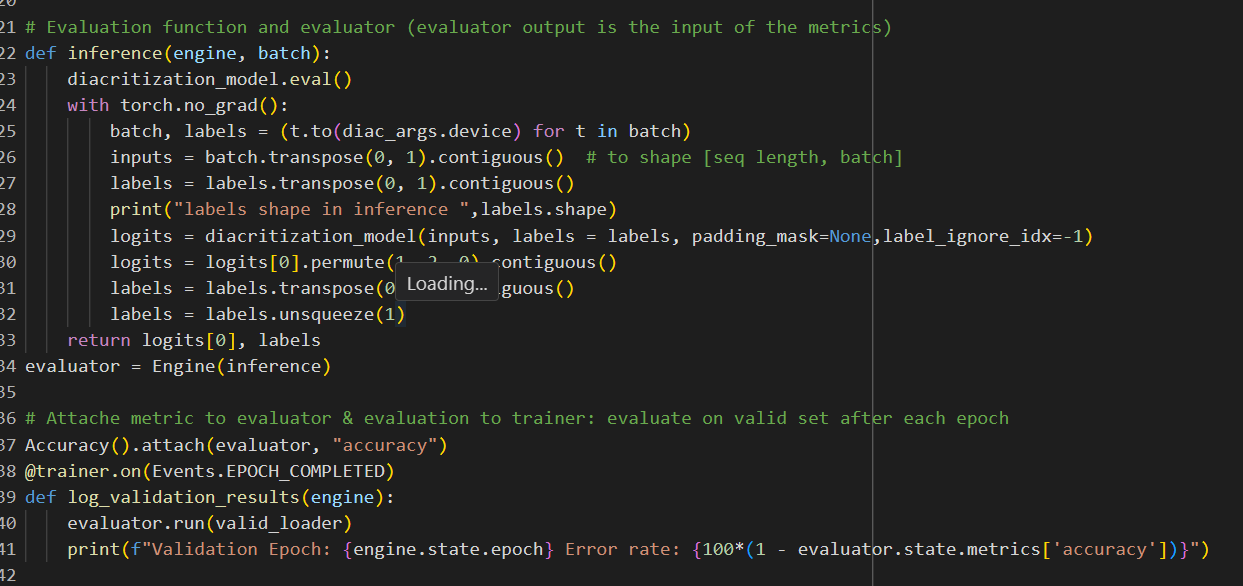
def inference(engine, batch):
diacritization_model.eval()
with torch.no_grad():
batch, labels = (t.to(diac_args.device) for t in batch)
inputs = batch.transpose(0, 1).contiguous() # to shape [seq length, batch]
labels = labels.transpose(0, 1).contiguous()
logits = diacritization_model(inputs, labels = labels, padding_mask=None,label_ignore_idx=-1)
return logits[0], labels
evaluator = Engine(inference)
# Attache metric to evaluator & evaluation to trainer: evaluate on valid set after each epoch
# Accuracy().attach(evaluator, "accuracy")
# @trainer.on(Events.EPOCH_COMPLETED)
# def log_validation_results(engine):
# evaluator.run(valid_loader)
# print(f"Validation Epoch: {engine.state.epoch} Error rate: {100*(1 - evaluator.state.metrics['accuracy'])}")
# Learning rate schedule: linearly warm-up to lr and then to zero
scheduler = PiecewiseLinear(optimizer, 'lr', [(0, 0.0), (diac_args.n_warmup, diac_args.lr),
(len(train_loader)*diac_args.n_epochs, 0.0)])
trainer.add_event_handler(Events.ITERATION_STARTED, scheduler)
# Add progressbar with loss
RunningAverage(output_transform=lambda x: x).attach(trainer, "loss")
ProgressBar(persist=True).attach(trainer, metric_names=['loss'])
# Save checkpoints and finetuning config
checkpoint_handler = ModelCheckpoint(diac_args.log_dir, 'finetuning_checkpoint', save_interval=1, require_empty=False)
# trainer.add_event_handler(Events.EPOCH_COMPLETED, checkpoint_handler, {'mymodel': diacritization_model})
torch.save(diac_args, os.path.join(diac_args.log_dir, 'fine_tuning_args.bin'))
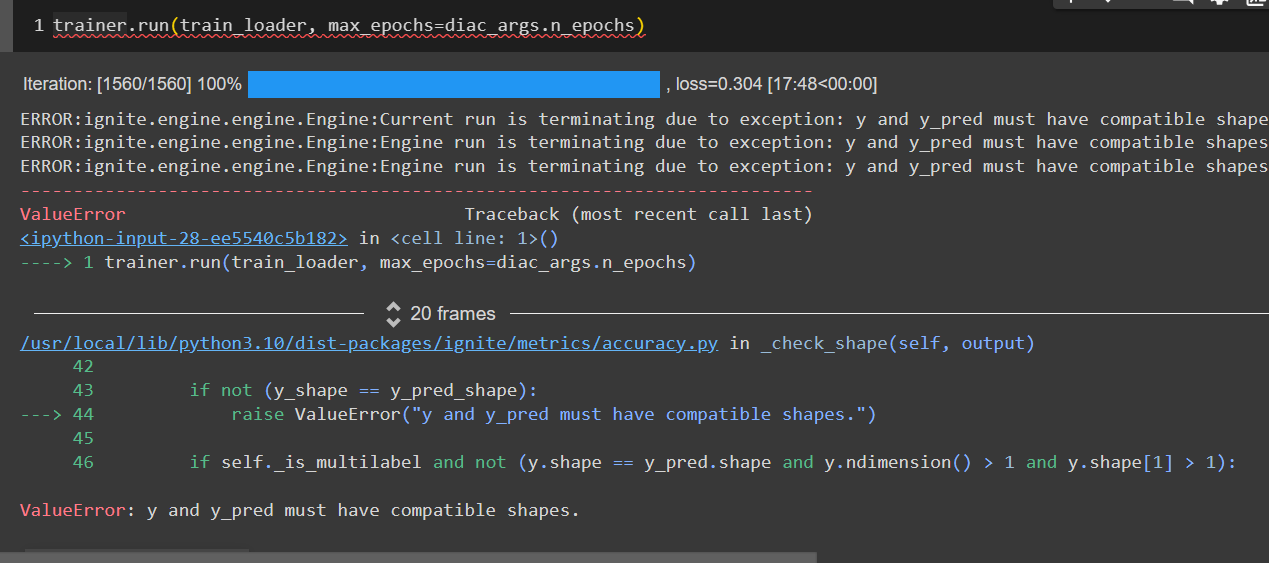
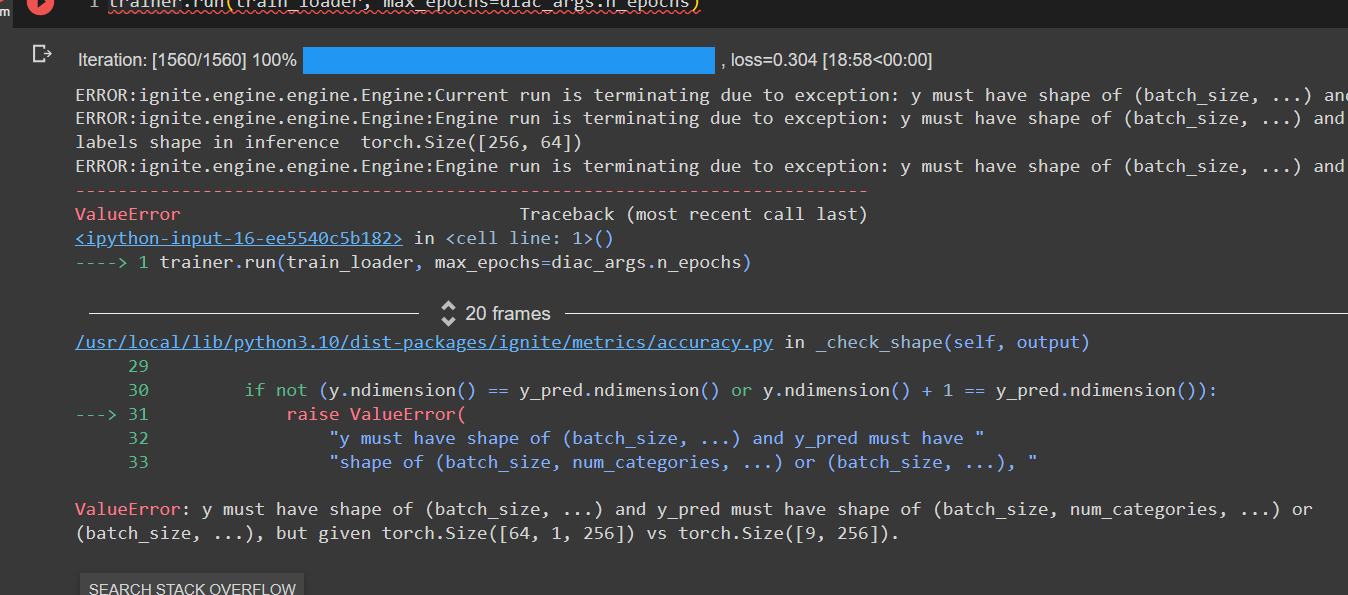
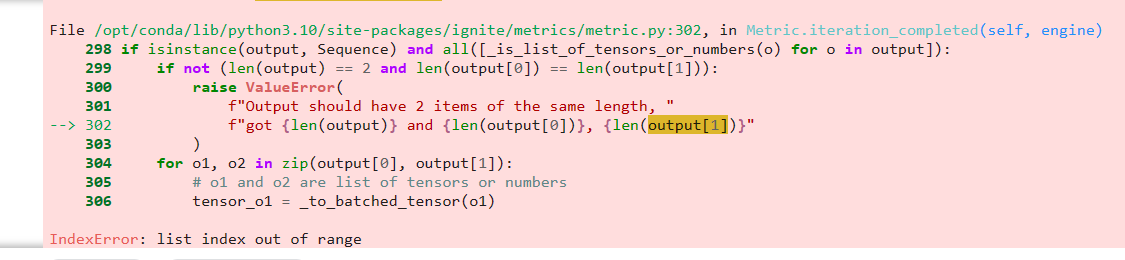
as you can see I have already commented the part of the code responsible for the validation accuracy calculation, cause whenever the epoch ends it breaks with error of not compatible shapes for the true labels and logits, for the first time the inference function was returning logits as tuple and the error was
the logits or y_pred has no attribute called ndimension cause it is tuple and then I made it return logits[0] so it returns the array of shape [256, 64, 9] → [seq_length, batch_size, num_categories]
and the labels are transposed to be in shape [seq_length, batch_size] so whenever the accuracy metric is being called it throws errors all of them around shape mismatch so anyone can help me with this cause I am training the model with loss being calculated and I want at least to see the result of the test accuracy, and if anyone can help me with the decode thing, I want to decode the logits value for the input sentence, like I read I saw that it needs softmax and argmax to get the index of the most probable output of the model then decode it like the encoded labels vocabulary, if you guys can help me with the decode code I’ll appreciate it.
thanks all and sorry for taking so long. ![]()