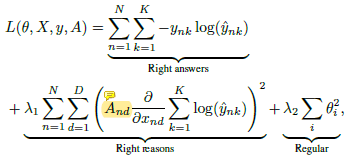
The first and third term are the Cross-entropy loss and L2 regularization, respectively and are already implemented in Pytorch. The matrix A is a binary mask with dims (Num of samples, W, H, #Color channel). The new loss can be called like this:
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=0.01) # L2 is weight decay
for batch in batches:
x, target = batch
logits = model(x)
loss = explanation_loss(logits, target, l_one, A[index])
loss.backward()
optimizer.zero_grad()
optimizer.step()
I am confused on how to implement the 2nd term (right reasons).
Specifically:
if my pytorch model outputs logits, I must first convert them to probabilities with softmax and then into a one-hot encoding to take the log, right?
How do I implement the input gradient here? (partial derivative w.r.t. x in the image)
You hardly ever need one hot labels, I don’t think you need them here. Also, I would use torch.nn.functional.cross_entropy_loss instead of re-instantiating the module over and over. You do need predictions, but these are per-class encoded anyways.
You would want to use log_softmax rather than softmax + log.
For the loss involving a gradient w.r.t. the inputs, you’d need to use use requires_grad_() on the inputs and then use gr_input, = torch.autograd.grad(sum_log_hat_y, input) to get the gradient of your loss computation.
If you believe your input gradients to be reasonably independent of the other inputs in the batch (this can be problematic for BatchNorm but is fine for most other things), you can sum over the batch before taking the gradient, this will make things much faster because you only need one gradient.
Hello @tom, thank you for the guidance. Now an error is thrown about trying to call the graph a second time when I call loss.backward(). But if I am correct, I just need the gradient values when computing input_grad and the first graph can be dropped. Do you have further advice on how to solve this without specifying retain_graph=True so I avoid an OOM error?
Below is my current pseudo-code:.
def explanation_loss(model, x, y, l_one):
logits = model(x)
ce = F.cross_entropy(logits, target)
if l_one==0:
return ce
sum_log_hat_y = torch.sum(F.log_softmax(logits, dim=1)).mean()
# same dims as x
input_grad, = torch.autograd.grad(sum_log_hat_y, x)
mask_matrix = largest_gradient_mask(input_grad)
mask_matrix = mask_matrix.float()
dot_prod = torch.dot(torch.flatten(mask_matrix), torch.flatten(input_grad))
right_reasons = l_one * (dot_prod) ** 2
return ce + right_reasons, mask_matrix
mask_list = []
for batch in clean_train_loader:
# Mask matrix and loss are calculated in a single pass
x, target = batch
x, target = x.to(device).requires_grad_(True), target.to(device)
optimizer.zero_grad()
loss, A_batch = explanation_loss(model, x, target, 0.01)
mask_list.append(A_batch)
loss.backward() # Runtime Error
optimizer.step()
The loss works as fine as cross entropy when l_one = 0.
However, it does not decrease when I pass a zero matrix. It should behave the same as above because the custom term is multiplied by zero. This is validated by the fact that my assertion statements pass. @tom does autograd.grad influence how the optimizer updates the model parameters, or is this a potential bug for autograd?
def explanation_loss(logits, x, target, \
mask_matrix=torch.zeros((len(dataset), 3, 32, 32)), \
l_one=0.001):
assert x.requires_grad == True
ce = F.cross_entropy(logits, target)
if l_one == 0:
return ce
sum_log_hat_y = torch.sum(F.log_softmax(logits, dim=1)).mean()
# same dims as x
input_grad, = torch.autograd.grad(sum_log_hat_y, x, retain_graph=True, create_graph=True)
dot_prod = torch.dot(torch.flatten(mask_matrix), torch.flatten(input_grad))
assert dot_prod == 0, dot_prod.item()
right_reasons = l_one * ((dot_prod) ** 2)
assert right_reasons == 0, right_reasons.item() # These assertions pass
return ce + right_reasons
I think the torch.dot is wrong. My understanding was that it should be * and then
right_reasons = l_one * ((dot_prod) ** 2).sum()
But this doesn’t explain why you would have trouble with the right_reasons term if the mask matrix is all zeros…
Do you have a toy example to demonstrate this, maybe form the paper?
@tom Oops, you’re right. I was following the original implementation on a perceptron too closely.
It seems that the model updates correctly on vanilla Pytorch, but it doesn’t on Pytorch Lightning. If you work with the latter, I made a notebook for you to reproduce the error, but otherwise I will post this in the PL community. Thanks again!