I’m looking for a way to replicate some behavior from Lua/Torch7’s nn.GPU. Basically one could split a single model across multiple GPUs, and then run that model backwards without having to modify the “Closure” function:
The key to this seems to have been the nn.GPU function in Torch7:
The intended use-case is not for model-parallelism where the models are executed in parallel on multiple devices, but for sequential models where a single GPU doesn’t have enough memory.
In trying to replicate this in PyTorch, I started trying to use nn.DataParallel:
However I still seem to have to manually convert the output of each set of model layers, to a single GPU. This single GPU then ends up having a really high memory usage that negates what I am trying to do. nn.DataParallel as I understand, is meant for batch sizes larger than 1, however I am only using a batch size of one (style transfer). The issue of nn.DataParallel using a lot of memory on a single GPU is documented here, here, and in many other posts.
Basically I am trying to separate a sequential model into a set of smaller models across multiple GPUs, so that one can use more GPU memory and thus larger inputs/outputs can be used. I am not sure that nn.DataParallel is the best option for what I am trying to do, but I am not aware of any alternatives which would work.
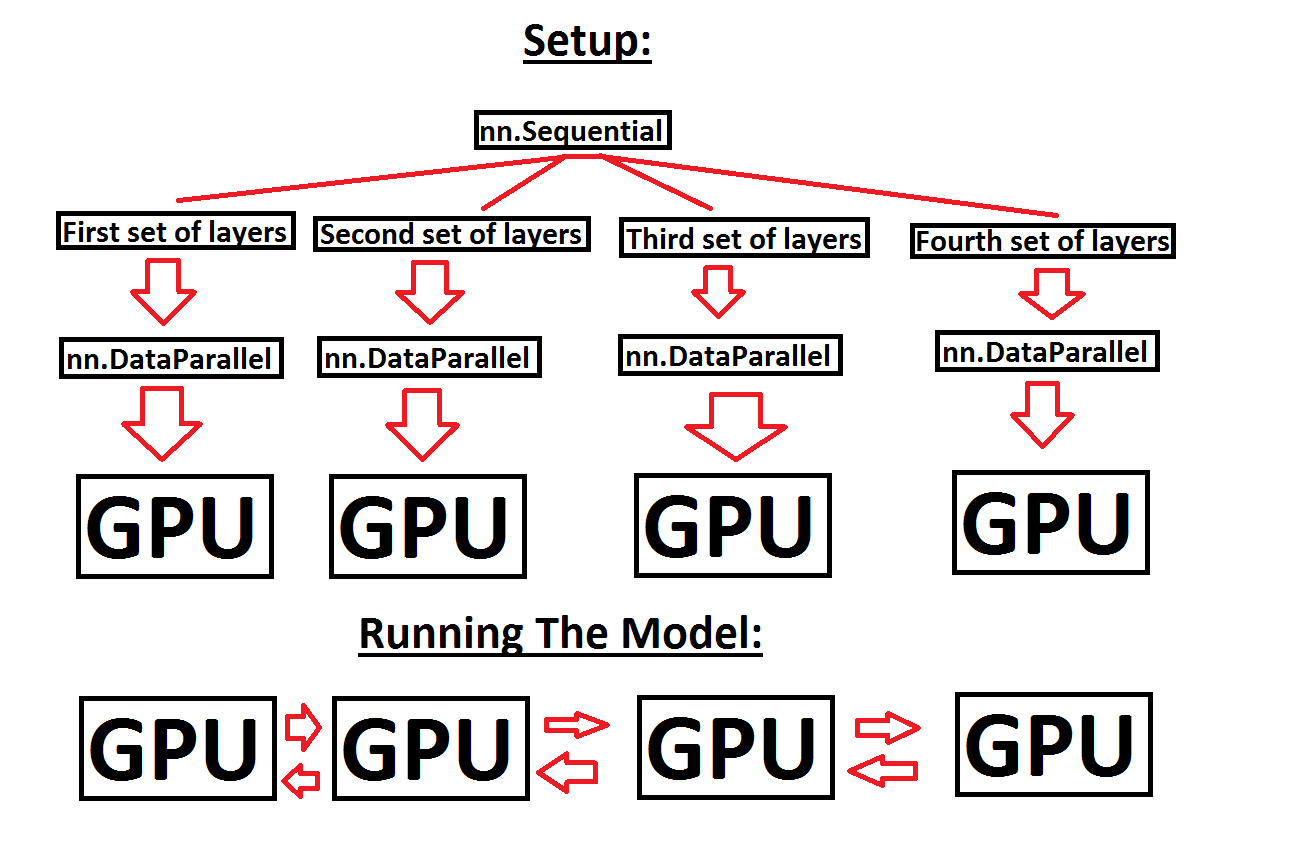
Here’s a basic MSPaint diagram of what I am currently doing in my code, with an example of 4 GPUs. The total number of GPUs, and how many layers to give each GPU, is meant to be entirely user controlled.