Hello everybody!
As I have read about the computation of Bidirectional RNNs (Bidirectional Outputs and Intermediate Inputs) and @vdw mentioned " I think most people just concatenate them before the next step, e.g., pushing through a Linear(2*hidden_size, output_size)". However, when I tried to implement the idea the forward hidden states of the 2nd layer are not equal to the defined bidirectional RNN.
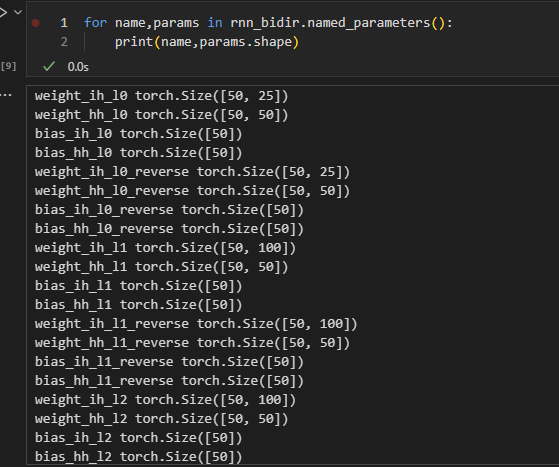
Here’s my code:
First I define the rnn_bidir as the standard Pytorch Bidirectional RNN, and rnn_forward_{order} are the ordinary RNN, so that i can stack their outputs for later investigation.
import torch
rnn_bidir = torch.nn.RNN(25, 50, 4,batch_first = True,bidirectional = True)
rnn_forward_1st = torch.nn.RNN(25, 50, 1,batch_first = True,bidirectional = False) #First hidden layer (50,25)
rnn_forward_2nd = torch.nn.RNN(100, 50, 1,batch_first = True,bidirectional = False) #2nd hidden layer (50,100), 100 is the concatenated forward and backward hidden states
rnn_forward_3rd = torch.nn.RNN(100, 50, 1,batch_first = True,bidirectional = False) #3rd hidden layer (50,100)
rnn_forward_4th = torch.nn.RNN(100, 50, 1,batch_first = True,bidirectional = False) #4th hidden layer (50,100)
rnn_backward_1st = torch.nn.RNN(25, 50, 1,batch_first = True,bidirectional = False) #Same as forward layers
rnn_backward_2nd = torch.nn.RNN(100, 50, 1,batch_first = True,bidirectional = False)
rnn_backward_3rd = torch.nn.RNN(100, 50, 1,batch_first = True,bidirectional = False)
rnn_backward_4th = torch.nn.RNN(100, 50, 1,batch_first = True,bidirectional = False)
After that, I assign the weights and biases of the rnn_bidir into the individual RNN layers
rnn_forward_1st.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l0)
rnn_forward_1st.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l0)
rnn_forward_1st.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l0)
rnn_forward_1st.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l0)
rnn_forward_2nd.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l1)
rnn_forward_2nd.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l1)
rnn_forward_2nd.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l1)
rnn_forward_2nd.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l1)
rnn_forward_3rd.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l2)
rnn_forward_3rd.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l2)
rnn_forward_3rd.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l2)
rnn_forward_3rd.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l2)
rnn_forward_4th.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l3)
rnn_forward_4th.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l3)
rnn_forward_4th.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l3)
rnn_forward_4th.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l3)
rnn_backward_1st.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l0_reverse)
rnn_backward_1st.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l0_reverse)
rnn_backward_1st.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l0_reverse)
rnn_backward_1st.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l0_reverse)
rnn_backward_2nd.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l1_reverse)
rnn_backward_2nd.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l1_reverse)
rnn_backward_2nd.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l1_reverse)
rnn_backward_2nd.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l1_reverse)
rnn_backward_3rd.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l2_reverse)
rnn_backward_3rd.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l2_reverse)
rnn_backward_3rd.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l2_reverse)
rnn_backward_3rd.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l2_reverse)
rnn_backward_4th.weight_ih_l0 = torch.nn.Parameter(rnn_bidir.weight_ih_l3_reverse)
rnn_backward_4th.weight_hh_l0 = torch.nn.Parameter(rnn_bidir.weight_hh_l3_reverse)
rnn_backward_4th.bias_ih_l0 = torch.nn.Parameter(rnn_bidir.bias_ih_l3_reverse)
rnn_backward_4th.bias_hh_l0 = torch.nn.Parameter(rnn_bidir.bias_hh_l3_reverse)
Then, I create the initialized hidden states of both forward and backward directions, and then concatenate then alternatively to feed into the rnn_bidir
hidden_forward = torch.randn(4,15,50)
hidden_backward = torch.randn(4,15,50)
hidden_bidir_init = torch.cat((hidden_forward[:1],hidden_backward[:1]),0)
for i,(hid_for,hid_back) in enumerate(zip(hidden_forward[1:],hidden_backward[1:])):
hidden_bidir_init = torch.cat((hidden_bidir_init,torch.cat((hid_for.unsqueeze(0),hid_back.unsqueeze(0)),0)),0)
input = torch.randn(15,5,25)
out_bidir, hidden_bidir = rnn_bidir(input, hidden_bidir_init)
After that, I first test on the 1st and 2nd layers that I define,
inverse_input = input[:,-1:]
for i,in_ in enumerate(input[:,:-1]):
inverse_input = torch.cat((inverse_input,input[:,-i-2:-i-1]),1)
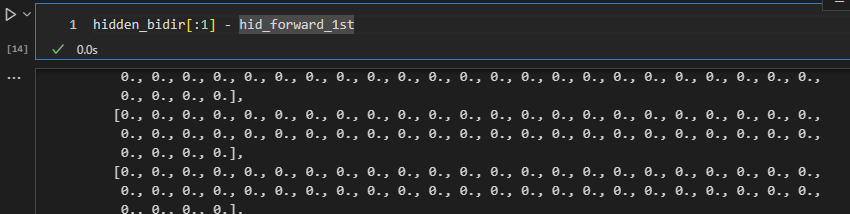
out_forward_1st ,hid_forward_1st = rnn_forward_1st(input,hidden_forward[:1])
out_backward_1st,hid_backward_1st = rnn_backward_1st(inverse_input,hidden_backward[:1])
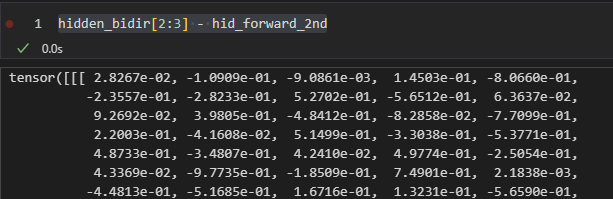
out_forward_2nd ,hid_forward_2nd = rnn_forward_2nd(torch.cat((out_forward_1st,out_backward_1st),-1),hidden_forward[1:2])
out_backward_2nd,hid_backward_2nd = rnn_backward_2nd(torch.cat((out_forward_1st,out_backward_1st),-1),hidden_backward[1:2])
For the 1st forward and backward layers, it works (the subtraction of hidden_bidir[:1] - hid_forward_1st is zeros, and so does the hid_backward_1st). However, when i step into the 2nd layer, the subtraction is not zeros anymore.
Question:
- If @vdw’s opinion is right, then why after concatenating the forward and backward states of the previous layer, it didn’t return the same results as Pytorch’s Bidirectional RNN? If not, could you please tell me the computation flow of the Bidirectional RNN in Pytorch?
- Does the backward have to concatenate the output of the forward hidden state as well? If not, why the shape of the weights in the hidden layers of bidirectional RNNs are (hidden_size, hidden_size*2) for both forward and backward direction?
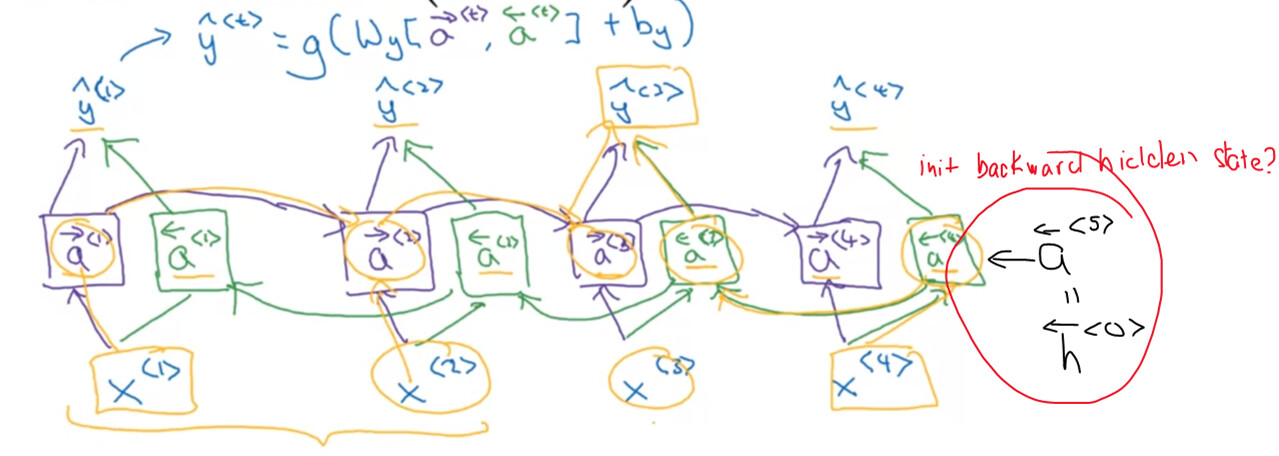
- Aside from the computation flow, how does Pytorch handle the initialized hidden_state (D*num_layers, N,h) for backward direction? Is it the initial state of the last timestep in the input sequence (start of the backward direction) - Like the picture below?
Thank you in advance!!