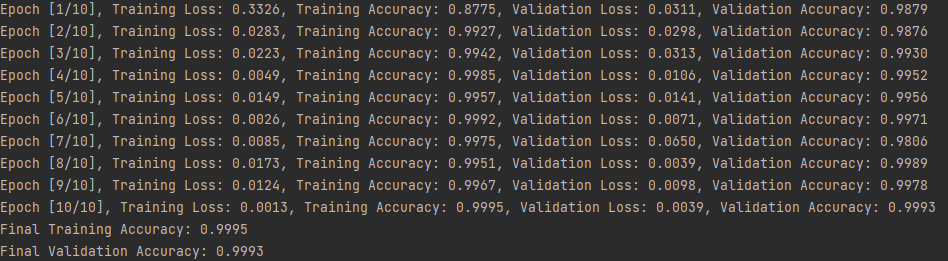
I trained a CNN model using Pytorch with high accuracy (~99%) and low loss (~0.002) in both the training set and the validation set. However, my model predicted the wrong image’s label even with images in the training dataset.
I used black and white images (1 channel) for my dataset. My dataset is balanced and has 6 labels. Each image’s size is 240px width and 180px height.
I tried to predict images in my training dataset using my trained model (~99% accuracy). I tried to predict in every folder (label) and got these results:
- Images in the first label got high accuracy (~99%)
- Images in the 5 other labels got very low accuracy (0-20%)
This is my code:
Data prepared code:
import matplotlib.pyplot as plt
import numpy as np
import os
import cv2
import random
import pickle
DATADIR = "../Data/"
# All categories you want your neural network to detect
CATEGORIES = ["Back", "Down", "Forward", "Left", "Right", "Up"]
# Checking all images in the data folder
for category in CATEGORIES:
path_image = DATADIR + category
# print(path_image)
for img in os.listdir(path_image):
img_array = cv2.imread(os.path.join(path_image, img), cv2.IMREAD_GRAYSCALE)
# print(img_array.shape)
training_data = []
def create_training_data():
for category in CATEGORIES:
path_image = DATADIR + category
class_num = CATEGORIES.index(category)
for img in os.listdir(path_image):
try:
img_array = cv2.imread(os.path.join(path_image, img), cv2.IMREAD_GRAYSCALE)
new_array = cv2.resize(img_array, (240, 180))
training_data.append([new_array, class_num])
except Exception as e:
pass
create_training_data()
random.shuffle(training_data)
random.shuffle(training_data)
random.shuffle(training_data)
X = [] # features
y = [] # labels
for features, label in training_data:
X.append(features)
y.append(label)
plt.imshow(X[0], cmap="gray")
plt.show()
X = np.array(X).reshape(-1, 240, 180, 1)
print(X.shape)
print(y[0])
pickle_out = open("Saved_Model/New_Model/X.pickle", "wb")
pickle.dump(X, pickle_out)
pickle_out.close()
pickle_out = open("Saved_Model/New_Model/y.pickle", "wb")
pickle.dump(y, pickle_out)
pickle_out.close()
CNN model code:
import torch
import torch.nn as nn
import torch.optim as optim
from torch import flatten
import pickle
import matplotlib.pyplot as plt
from tqdm import tqdm
from torchsummary import summary
X = pickle.load(open("Saved_Model/New_Model/X.pickle", "rb"))
y = pickle.load(open("Saved_Model/New_Model/y.pickle", "rb"))
# normalizing data (a pixel goes from 0 to 255)
X = torch.tensor(X / 255.0, dtype=torch.float32, device='cpu')
y = torch.tensor(y, dtype=torch.long, device='cpu')
# Define the CNN model
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# initialize first set of CONV => RELU => POOL layers
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32,
kernel_size=(3, 3), padding=1)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# initialize second set of CONV => RELU => POOL layers
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64,
kernel_size=(3, 3), padding=1)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128,
kernel_size=(3, 3), padding=1)
self.relu3 = nn.ReLU()
self.maxpool3 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# self.dropout = nn.Dropout(0.25)
# initialize first (and only) set of FC => RELU layers 42240
self.fc1 = nn.Linear(in_features=84480, out_features=128)
self.relu4 = nn.ReLU()
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(in_features=128, out_features=64)
self.relu5 = nn.ReLU()
self.dropout = nn.Dropout(0.5)
# initialize our softmax classifier
self.fc3 = nn.Linear(in_features=64, out_features=6)
self.logSoftmax = nn.LogSoftmax(dim=1)
def forward(self, x):
# pass the input through our first set of CONV => RELU =>
# POOL layers
# print(x.shape)
x = self.conv1(x)
x = self.relu1(x)
x = self.maxpool1(x)
# pass the output from the previous layer through the second
# set of CONV => RELU => POOL layers
# print(x.shape)
x = self.conv2(x)
x = self.relu2(x)
x = self.maxpool2(x)
# print(x.shape)
x = self.conv3(x)
x = self.relu3(x)
x = self.maxpool3(x)
x = x.view(-1, 84480)
x = self.fc1(x)
x = self.relu4(x)
x = self.dropout(x)
x = self.fc2(x)
x = self.relu5(x)
x = self.dropout(x)
x = self.fc3(x)
output = self.logSoftmax(x)
return output
model = CNN().cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters())
# Train the model
num_epochs = 10
batch_size = 32
train_size = int(X.shape[0] * 0.85)
train_dataset = torch.utils.data.TensorDataset(X[:train_size], y[:train_size])
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataset = torch.utils.data.TensorDataset(X[train_size:], y[train_size:])
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
train_acc_list, val_acc_list = [], []
for epoch in range(num_epochs):
train_loss, train_acc = 0, 0
model.train()
for i, (inputs, labels) in enumerate(train_loader):
inputs, labels = inputs.cuda(), labels.cuda()
optimizer.zero_grad()
outputs = model(inputs.permute(0, 3, 2, 1))
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
train_acc += (outputs.argmax(dim=1) == labels).sum().item()
train_loss /= len(train_loader.dataset)
train_acc /= len(train_loader.dataset)
train_acc_list.append(train_acc)
val_loss = 0
val_acc = 0
model.eval()
with torch.no_grad():
for inputs, labels in val_loader:
inputs, labels = inputs.cuda(), labels.cuda()
outputs = model(inputs.permute(0, 3, 2, 1))
loss = criterion(outputs, labels)
val_loss += loss.item() * inputs.size(0)
val_acc += (outputs.argmax(dim=1) == labels).sum().item()
val_loss /= len(val_loader.dataset)
val_acc /= len(val_loader.dataset)
val_acc_list.append(val_acc)
print(f"Epoch [{epoch + 1}/{num_epochs}], Training Loss: {train_loss:.4f}, Training Accuracy: {train_acc:.4f}, "
f"Validation Loss: {val_loss:.4f}, Validation Accuracy: {val_acc:.4f}")
# Save model
torch.save(model.state_dict(), 'Saved_Model/New_Model/CNN_Model.pth')
# Print final training and validation accuracy
final_train_acc = train_acc_list[-1]
final_val_acc = val_acc_list[-1]
print(f"Final Training Accuracy: {final_train_acc:.4f}")
print(f"Final Validation Accuracy: {final_val_acc:.4f}")
# Plotting the accuracy changes during the training phase
plt.figure(figsize=(8, 6))
plt.plot(train_acc_list, label='Training Accuracy')
plt.plot(val_acc_list, label='Validation Accuracy')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
summary(model, input_size=(1, 180, 240))
Code to predict every folder (label):
import os
import torch
import torchvision.transforms as transforms
import torch.nn as nn
from PIL import Image
# Set the path to the folder containing your images
folder_path = '../Data/Down'
CATEGORIES = ["Back", "Down", "Forward", "Left", "Right", "Up"]
# Load the trained model
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# initialize first set of CONV => RELU => POOL layers
self.conv1 = nn.Conv2d(in_channels=1, out_channels=32,
kernel_size=(3, 3), padding=1)
self.relu1 = nn.ReLU()
self.maxpool1 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# initialize second set of CONV => RELU => POOL layers
self.conv2 = nn.Conv2d(in_channels=32, out_channels=64,
kernel_size=(3, 3), padding=1)
self.relu2 = nn.ReLU()
self.maxpool2 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
self.conv3 = nn.Conv2d(in_channels=64, out_channels=128,
kernel_size=(3, 3), padding=1)
self.relu3 = nn.ReLU()
self.maxpool3 = nn.MaxPool2d(kernel_size=(2, 2), stride=(2, 2))
# self.dropout = nn.Dropout(0.25)
# initialize first (and only) set of FC => RELU layers 42240
self.fc1 = nn.Linear(in_features=84480, out_features=128)
self.relu4 = nn.ReLU()
self.fc2 = nn.Linear(in_features=128, out_features=64)
self.relu5 = nn.ReLU()
# initialize our softmax classifier
self.fc3 = nn.Linear(in_features=64, out_features=6)
self.logSoftmax = nn.LogSoftmax(dim=1)
def forward(self, x):
x = self.conv1(x)
x = self.relu1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.relu2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.relu3(x)
x = self.maxpool3(x)
x = x.view(-1, 84480)
x = self.fc1(x)
x = self.relu4(x)
x = self.fc2(x)
x = self.relu5(x)
x = self.fc3(x)
output = self.logSoftmax(x)
return output
model = CNN()
model.load_state_dict(torch.load("Saved_Model/New_Model/CNN_Model.pth"))
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
model.eval()
# Define image transformations
transform = transforms.Compose([
transforms.ToTensor()
# transforms.Normalize(mean=(0.5), std=(0.5))
])
# Open the output file in write mode
output_file = open('..\Code\Prediction_Accuracy\Down.txt', 'w')
total_file = 0
accuracy_file = 0
for filename in os.listdir(folder_path):
img_path = os.path.join(folder_path, filename)
img = Image.open(img_path).convert('1')
img_tensor = transform(img).unsqueeze(0).to(device)
total_file += 1
# Predict the image class
with torch.no_grad():
predictions = model(img_tensor)
predicted_class = predictions.argmax().item()
if predicted_class == 1:
accuracy_file += 1
output_file.write(f"Image: {filename}, Prediction: {predicted_class}\n")
print(f"accuracy: {accuracy_file/total_file}")
output_file.write(f"accuracy: {accuracy_file/total_file}")
output_file.close()