Hi,
I am implementing high order derivatives for PyTorch. All existing implementation I saw require that the target tensor will be scalar, while my implementation is for any arbitrary tensor.
I developed a functon that for a model (or function) model and input values x, it will return derivatives up to the orderth order, for all x values. When passing a NN, this function must be called at the start of each step\epoch, because it zeros the grads of the optimizer’s params.
def get_high_order_analytic_derivative(model, x, order, optimizer=None):
result = []
x_grad = model(x)
result.append(x_grad)
while order > 0:
x.grad = None
x_grad.backward(torch.ones_like(x), create_graph=True, retain_graph=True)
x_grad = x.grad
result.append(x_grad)
order -= 1
x.grad = None
if optimizer is not None:
optimizer.zero_grad() # remove trace of calculations from the parameters
return result
I confirmed the correctness of the function with this example:
a = torch.randn(10, requires_grad=True)
f, df, ddf = get_high_order_analytic_derivate(torch.sin, a, 2)
f
Out[95]:
tensor([ 0.7344, 0.9864, 0.4804, -0.9276, -0.5895, -0.2465, -0.9672, 0.9168,
0.3063, -0.6023], grad_fn=<SinBackward>)
df
Out[96]:
tensor([ 0.6788, -0.1645, 0.8770, 0.3736, 0.8078, 0.9691, -0.2539, -0.3994,
0.9519, 0.7983], grad_fn=<CopyBackwards>)
ddf
Out[97]:
tensor([-0.7344, -0.9864, -0.4804, 0.9276, 0.5895, 0.2465, 0.9672, -0.9168,
-0.3063, 0.6023], grad_fn=<CopyBackwards>)
f + ddf
Out[98]: tensor([0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], grad_fn=<AddBackward0>)
I want a NN to learn the sine function, and one of the loss terms is MSE between (f + ddf) and zeros_like(f + ddf), over some grid of inputs. However, I found that this specific term harms the convergence to my desired model. It think it smoothes my model.
What could be the problem? Is there a problem with using differential equations as loss terms when training NNs? Or maybe my way of calculating the derivatives is not desirable? (notice how I call zero grad so all the calculations shouldn’t change the state of the model)
This is an illustration of adding it as a loss term with growing significance:
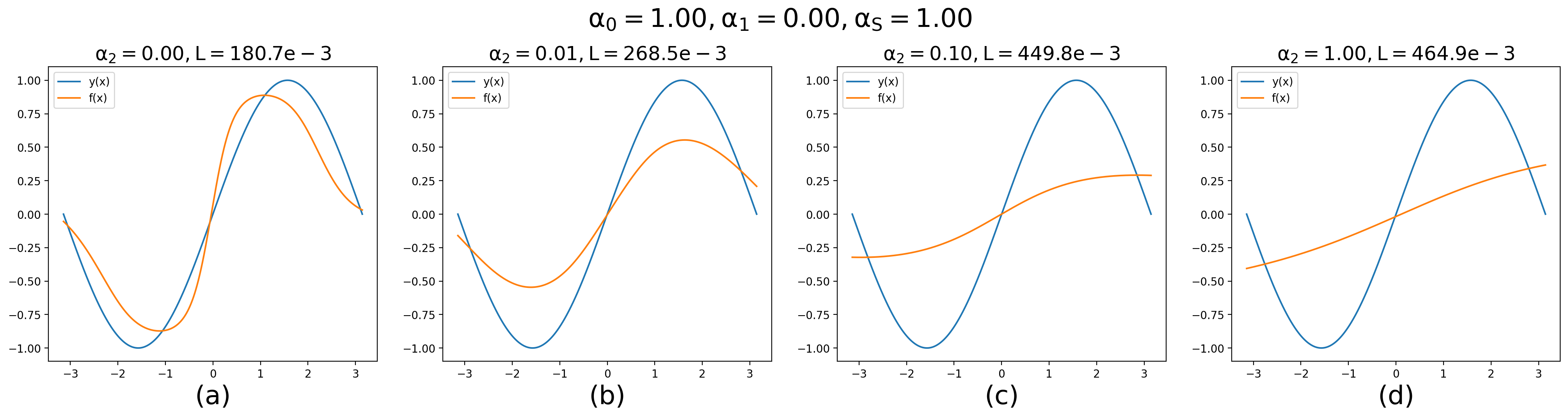
The blue line is actual sin and the orange is my model.