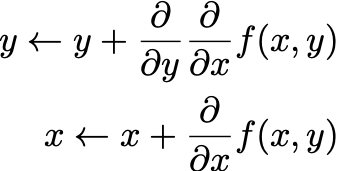My question is: is this the best (and most performant) way to do this? x.grad = ddx is not so bad, but when it’s all the parameters of several neural networks, this involves a lot of careful matching of gradients to variables and a lot of room for error.
Thanks!
I won’t say anything about performance, but don’t do this! As you rightly point out, x.grad = ... is playing with the fire.
A better way to use PyTorch’s capabilities properly is to detach the things you don’t want to backward into. In order to do the second derivative, you need to have a copy of x that is detached, but requires gradient.
So this is what your sample would look like:
Thanks for the response. So in the actual code, f() is a neural network (actually several) and x is the parameters of these networks.
I thought that the way to apply .detached to the parameters would be something like this:
import torch
x = torch.ones(1, requires_grad=True)
dense = torch.nn.Linear(1, 1)
for var in dense.parameters():
var.requires_grad = False
y = dense(x)
print(torch.autograd.grad(y, dense.parameters()))
This raises
RuntimeError: One of the differentiated Tensors does not require grad
because torch.no_grad() seems to prevent gradients from flowing back to x.
So I assume that this is not the correct way to detach the parameters of the networks, right?
I must admit that I don’t even know what that bit of code might try to achieve (I prefer .requires_grad_(False), but that obviously is in conflict with takimg the grad?). Maybe just leaving the nets as they are is a good strategy or you can describe what you are trying to compute or how it compares to your initial posting.
Sure. Referencing the equations in my initial post, f is essentially my objective function. Both x and y are parameters of neural networks. I am trying to learn x values that maximize f(x, y). I am trying to learn y values that yield large gradients for f(x,y). Thus the update rule for y is in the direction of greater df/dx.
The code in my previous post was an attempt at applying .detach to the parameters of a neural network, which it seemed like you were suggesting in your post.
Hope that clarifies things a little. Also, thank you for your help.
thanks for elaborating on your use case.
When you say large gradients, do you have a specific norm in mind? I think you need to specify that to go multi-dimensional (if x isn’t scalar, I think that the update rule in your original runs into trouble with dimensionality.)
I’m not entirely sure what is the best way to “isolate” the two backwards passes in full generality. Does the function f factor into “application of NNs” and “compute loss”? Then detaching the outputs of the NNs might work well.
When you say large gradients , do you have a specific norm in mind?
Currently, I am using the global l2-norm:
def global_norm(grads):
norm = 0
for grad in grads:
norm += grad.norm(2)**2
return norm**.5
Does the function f factor into “application of NNs” and “compute loss”?
When you say “factor” here, I’m assuming you don’t mean multiplicative factorization. Perhaps it will clarify to mention that I have settled on an intermediate solution that is not very performant. Essentially:
g_optimizer.zero_grad()
f_optimizer = optim.Adam(f.parameters())
g_optimizer = optim.Adam(g.parameters())
f_grad = torch.autograd.grad(compute_f_loss(), f.parameters())
global_norm(f_grad).backward() # this assigns grads to both f.parameters() and g.parameters()
g_optimizer.step() # this only steps g.parameters()
f_optimizer.zero_grad() # this clears the gradients assigned to f.parameters()
compute_f_loss().backward()
f_optimizer.step() # this only steps f.parameters()
There are two performance problems:
It requires two backward passes, which is very slow. It would be great if I could reuse f_grad instead of recomputing it with compute_f_loss().backward().
It requires two calls to compute_f_loss(). This might be remedied with retain_graph=True.
By factor I mean that you spell out the call to f and g in the above code snippet and separate it from the loss.
In that case you can adapt the thing I wrote about your specific case by detaching the outputs of f and g before feeding them into the loss similar to what I did with your original example and get the right thing.
I realize that one thing that was not clear is that the compute_f_loss() actually computes a loss that is a function of the output of fand of g. Essentially, the output of g is fed into f.
The problem with detaching the outputs of f and g before feeding them into the loss is that I need the gradient of calculate_f_loss() with respect to f.parameters() and then I need the 2nd order gradient with respect to g.parameters(). If I detached the outputs of f and g, then calculate_f_loss().backward() would not populate the .grad fields of f.parameters() or g.parameters().
One thing that we didn’t quite clear up from earlier was how exactly to .detach() the parameters of a neural network. Would I have to create a copy of the neural network somehow? I think as soon as we clear that up, I could implement something like what you first proposed. Or were you suggesting detaching the output of the network instead of it’s parameters?
I should add that, as a newcomer to Torch, I’m not exactly sure what .detach() does. My interpretation of the docs is that it acts something like tf.stop_gradient in Tensorflow, preventing gradients from flowing through the variable. But if that is the case, then what does calling x.detach().requires_grad_() do? Does this essentially create a copy of the x node in the graph with all the same in- and out-edges? And what is the performance benefit to doing this?
Hi Thomas,
So I had a chance to implement this and test it against the original version. The two versions seem to perform identically, both in terms of outputs and runtime. Both are very slow with the forward pass and backward pass accounting for the majority of the runtime.
So my questions are:
Is it possible to avoid the compute_f_loss().backward() call by somehow reusing f_grad? (This would avoid a second backward pass.)
Is it possible to reuse the first call to compute_f_loss() so that the forward pass only needs to be done once?
It’s hard to debug this without looking at the code. You can definitely avoid .backward through the nets several times by just summing the two loss components. The bits that are necessarily evaluated twice in the forward won’t magically go away for the backward, though.
The issue is not calling .backward twice. The issue is redundant backward passes. Specifically: f_grad requires a backward pass and compute_f_loss().backward() requires a backward pass.
I can post my code but it is long and complicated. The small example I gave in an earlier post had all the same issues.
I don’t know if this is helpful, but if I were working in tensorflow, I would compute f_grad with tf.gradients and then I could feed those same gradients to the optimizer using opimizer.apply_gradients(variables, gradients). If torch has some kind of similar mechanism, it would solve my issue.
Would retain_graph in-between optim steps here save you the recompute of f? The semantics will be different, though (the optim steps for f, g would fall in lockstep).