How does one create a permanently partially connected linear layer?
I am trying to create a Linear layer where certain weights are held at zero and skipped during backpropagation so the weight doesn’t change from zero.
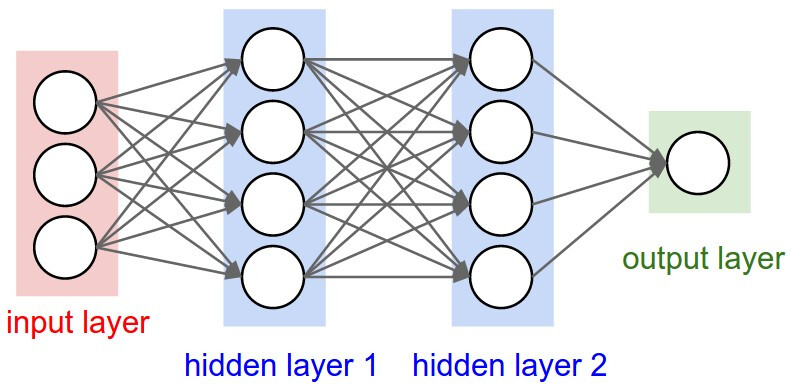
In the below image, imagine one of the connecting lines having a permanent weight of zero preventing communication between two neurons or between an input and neuron.
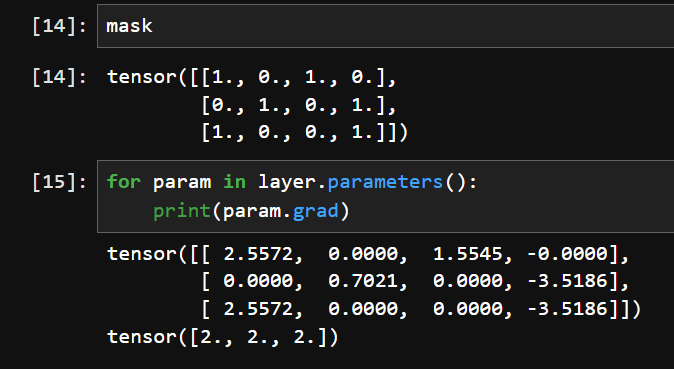
I’ve been trying to accomplish this by experimenting at the tensor level by setting
requires_gradient = False
for the scalar tensor at some index of a containing tensor, but I can’t get it to work.
After seeing the error message:
RuntimeError: you can only change requires_grad flags of leaf variables. If you want to use a computed variable in a subgraph that doesn't require differentiation use var_no_grad = var.detach().
I’ve tried detaching the scalar tensor and re-attaching it to the containing tensor, but requires_grad changes to True when the detached tensor is reattached and I end up right where I started.
Is there any way to hold a linear layer weight at zero through backpropagation? (i.e. backpropagation does not propagate through the connection - as if it were not there.)