I have been beating my head against the wall and come to the group to see if there is anything that looks like a culprit of very poor performance in a simple Two-Tower model. When i look at a hold out (future time period) set of customer -product interactions, the hit rate is far worse than just random products being offered. I am looking at evaluating at a top 5 product suggestion for the offline evaluation.
The model is very simple and is just a dot product of the cust and product embeddings. There are around 5,000 products and 5.6 million customers:
import torch
import torch.nn as nn
import torch.nn.functional as F
class TwoTowerMF(nn.Module):
def __init__(self, n_items, n_users, emb_dim):
super(TwoTowerMF, self).__init__()
self.emb_dim = emb_dim
self.item_emb = nn.Embedding(num_embeddings=n_items, embedding_dim=self.emb_dim, padding_idx=0)
self.user_emb = nn.Embedding(num_embeddings=n_users, embedding_dim=self.emb_dim, padding_idx=0)
self.dot = torch.matmul
def forward(self, items, users):
item_emb = self.item_emb(items)
user_emb = self.user_emb(users)
score = self.dot(user_emb, item_emb.t())
return score
The dataset uses the interactions held in memory. The item ID, customer ID and CSP which is just the probability that the item would be in the batch is yielded :
class interactionDataset(Dataset):
def __init__(self, item_user_inters):
self.inters = torch.LongTensor(item_user_inters[:,0:2]) # user and item
self.csp = torch.Tensor(item_user_inters[:,2]) # csp
def __len__(self):
return len(self.inters) # number interactions
def __getitem__(self, idx):
inter = self.inters[idx]
csp = self.csp[idx]
return inter[0], inter[1], csp # first array are item ID, second are user ID, third is csp
Im using DDP with a 4 GPU instance
train_ds = interactionDataset(pdf_ints_train)
if args.is_distributed:
# distributed training sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_ds, num_replicas=args.world_size, rank=rank
)
train_loader = DataLoader(train_ds,
shuffle= not args.is_distributed,
sampler= train_sampler if args.is_distributed else None,
batch_size=args.batch_size_train,
drop_last=False,
num_workers = args.num_workers)
The training loop is straight forward (I have tried with and without the adjustment to the loss based on the csp).
def train(args, model, device, train_loader, optimizer, epoch, loss_fn, rank):
model.train()
train_loss = 0.0
b_sz = len(next(iter(train_loader))[0])
print(f"[GPU{args.rank}] Epoch {epoch} | Batchsize: {b_sz}")
for batch_idx, (items, custs, csp) in enumerate(train_loader):
custs = custs.to(device)
items = items.to(device)
csp = csp.to(device)
optimizer.zero_grad()
# Forward pass
scores = model(items, custs)
# Compute Loss
loss = loss_fn(scores - torch.log(csp), torch.eye(custs.shape[0]).to(device))
train_loss += loss.item()
# Backward pass
loss.backward()
optimizer.step()
The loss is in-batch soft max which i think is setup just like Tensorflow recommenders.
model = TwoTowerMF(n_items=n_items+1, n_users=n_users+1, emb_dim=args.emb_dim)
# must come before call to DDP
model.to(device)
if args.is_distributed:
model = DDP(model,device_ids=[local_rank])
# Pin each GPU to a single library process
torch.cuda.set_device(local_rank)
loss_fn = nn.CrossEntropyLoss(reduction='sum')
optimizer = torch.optim.Adam(model.parameters(), lr = args.lr * math.sqrt(args.num_gpus))
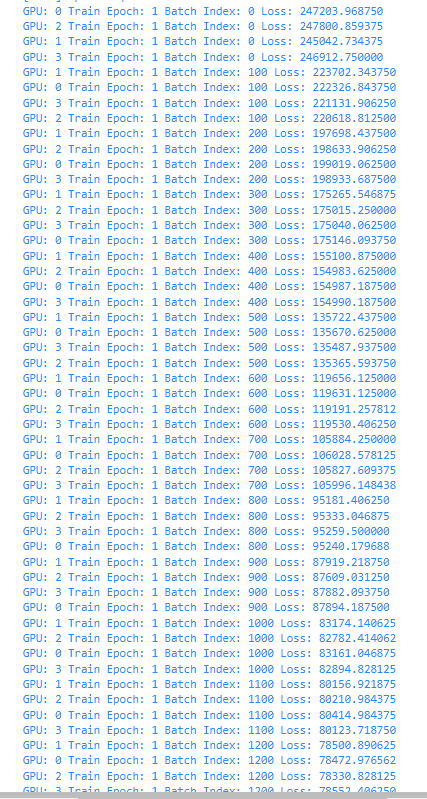
I have tried various learning rates, batch sizes etc and the model is always horrible.
Looking the loss for the first epoch, the model decreases loss in each batch but rough hits a period where it stops much improvement.