Dear All
I would like to have a better understanding on how LSTM is handling batches. As I am working on image captioning, if I have an embedding matrix of dimensions (batch_size, len, embed) like in figure 1.
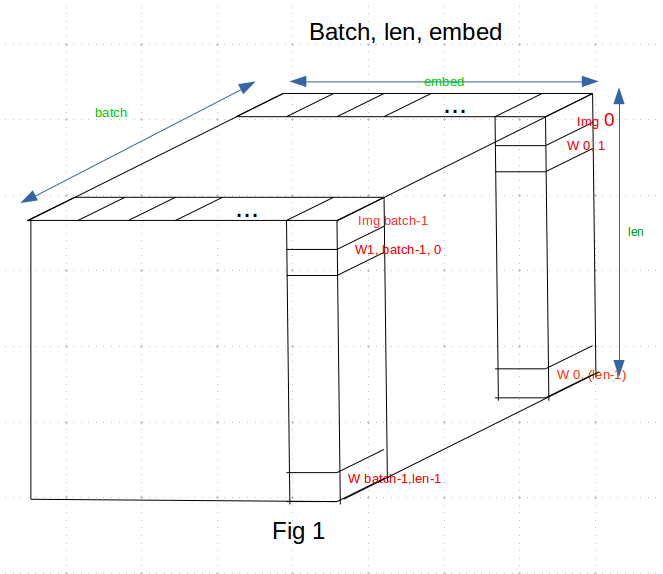
If I set batch_first= true, how the LSTM cell is processing the batch?
Is it by slicing along dim=2, first taking all the features vectors of all images and then the first embed word of all images and so on as it is depicted on Fig2 :
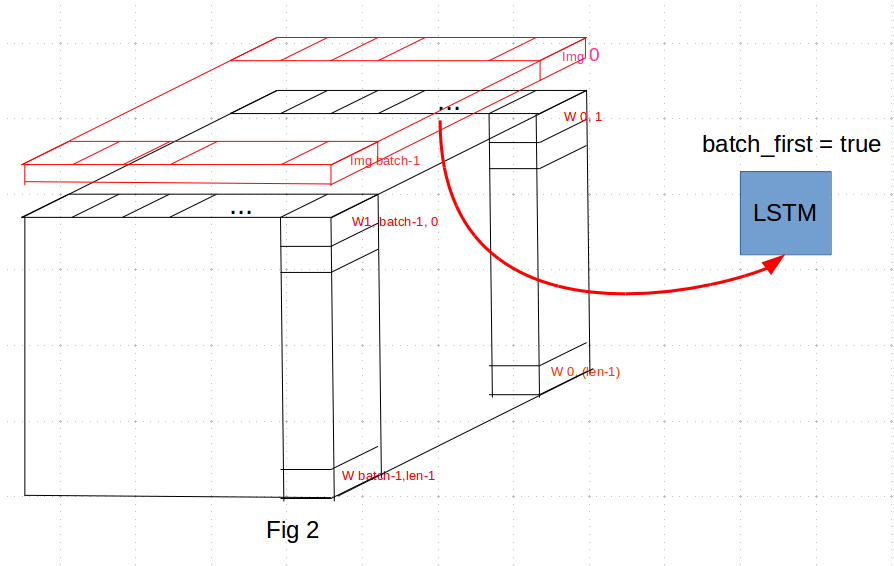
or is it by slicing along dim = 0, first taking the first features vector of img0 along with the sequence of embed words describing it and then the second img + words and so on as it is described in Fig 3?
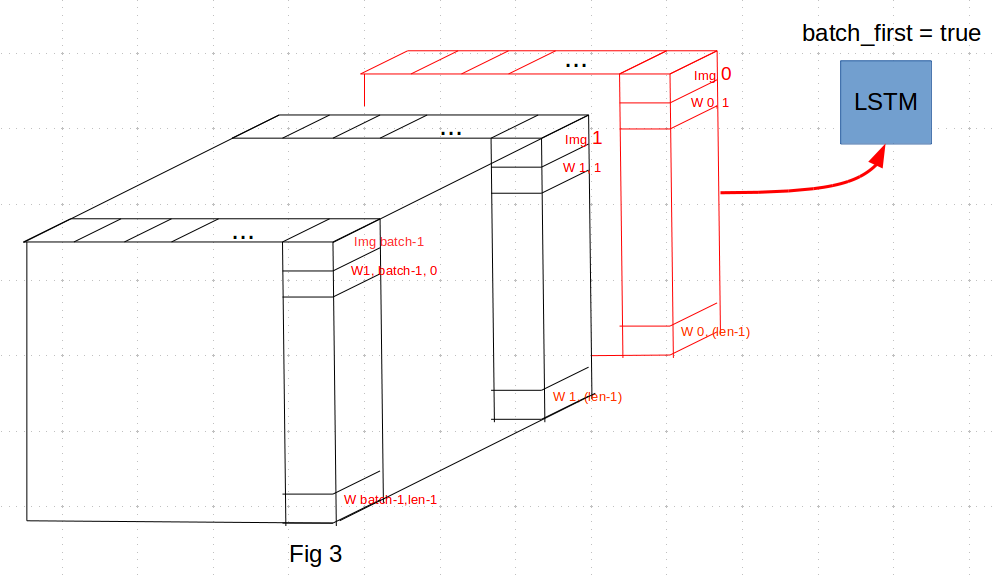
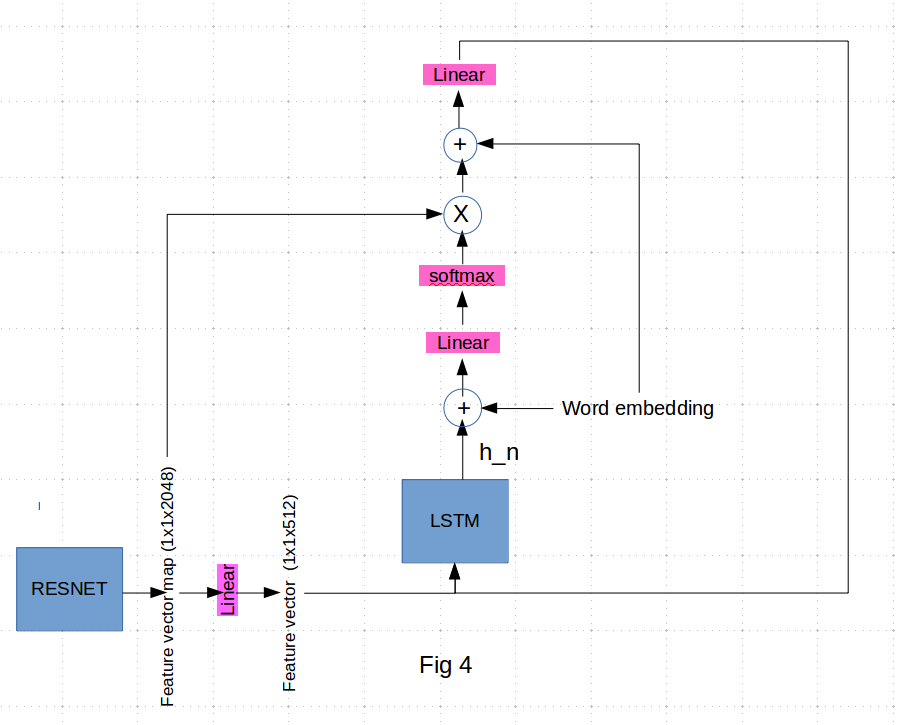
I am asking this also to understand the code below which is a implementation of the attention mechanism using the 1x1x2048 vector from resnet (Fig4)
So far it does not work I mean the loss never went under 5, so I am trying to understand why, and one step of the algorithm (in_vector = packed[start:start+batch_size].view(batch_size, 1, -1)) is slicing the input matrix like in the Fig2. So I wanted to know if it is correct.
def forward(self, features, cnn_features, captions, lengths):
"""Decode image feature vectors and generates captions."""
embeddings = self.embed(captions)
embeddings = torch.cat((features.unsqueeze(1), embeddings), 1)
packed, batch_sizes = pack_padded_sequence(embeddings, lengths, batch_first=True)
hiddenStates = None
start = 0
for batch_size in batch_sizes:
in_vector = packed[start:start+batch_size].view(batch_size, 1, -1)
start += batch_size
if hiddenStates is None:
hiddenStates, (h_n , c_n) = self.lstm(in_vector)
hiddenStates = torch.squeeze(hiddenStates)
else:
h_n, c_n = h_n[:,0:batch_size,:], c_n[:,0:batch_size,:]
info_vector = torch.cat((in_vector, h_n.view(batch_size, 1, -1)), dim=2)
attention_weights = self.attention(info_vector.view(batch_size, -1))
attention_weights = self.softmax(attention_weights)
attended_weights = cnn_features[0:batch_size] * attention_weights
attended_info_vector = torch.cat((in_vector.view(batch_size, -1), attended_weights), dim=1)
attended_in_vector = self.attended(attended_info_vector)
attended_in_vector = attended_in_vector.view(batch_size, 1, -1)
out, (h_n , c_n) = self.lstm(attended_in_vector, (h_n, c_n))
hiddenStates = torch.cat((hiddenStates, out.view(batch_size, -1)))
hiddenStates = self.linear(hiddenStates)
return hiddenStates
The function implements this workflow:
Thank you very much for taking the time to read this topic