What do you mean by saying the following sentence? “this assumes the different loss functions are used to compute grads for the same parameters”.
And what does a GAN-like situation refer to?
I am a little confused and not sure when to use (loss1 + loss2).backward() or loss1.backward(retain_graph=True) loss2.backward(). Why is one more efficient than the other? Are these two methods mathematically equivalent?
According to Sam Bobel in Stack Overflow - What does the parameter retain_graph mean in the Variable’s backward() method? , these two methods are not mathematically equivalent if one uses adaptive gradient optimizers like ADAM, as shown below:
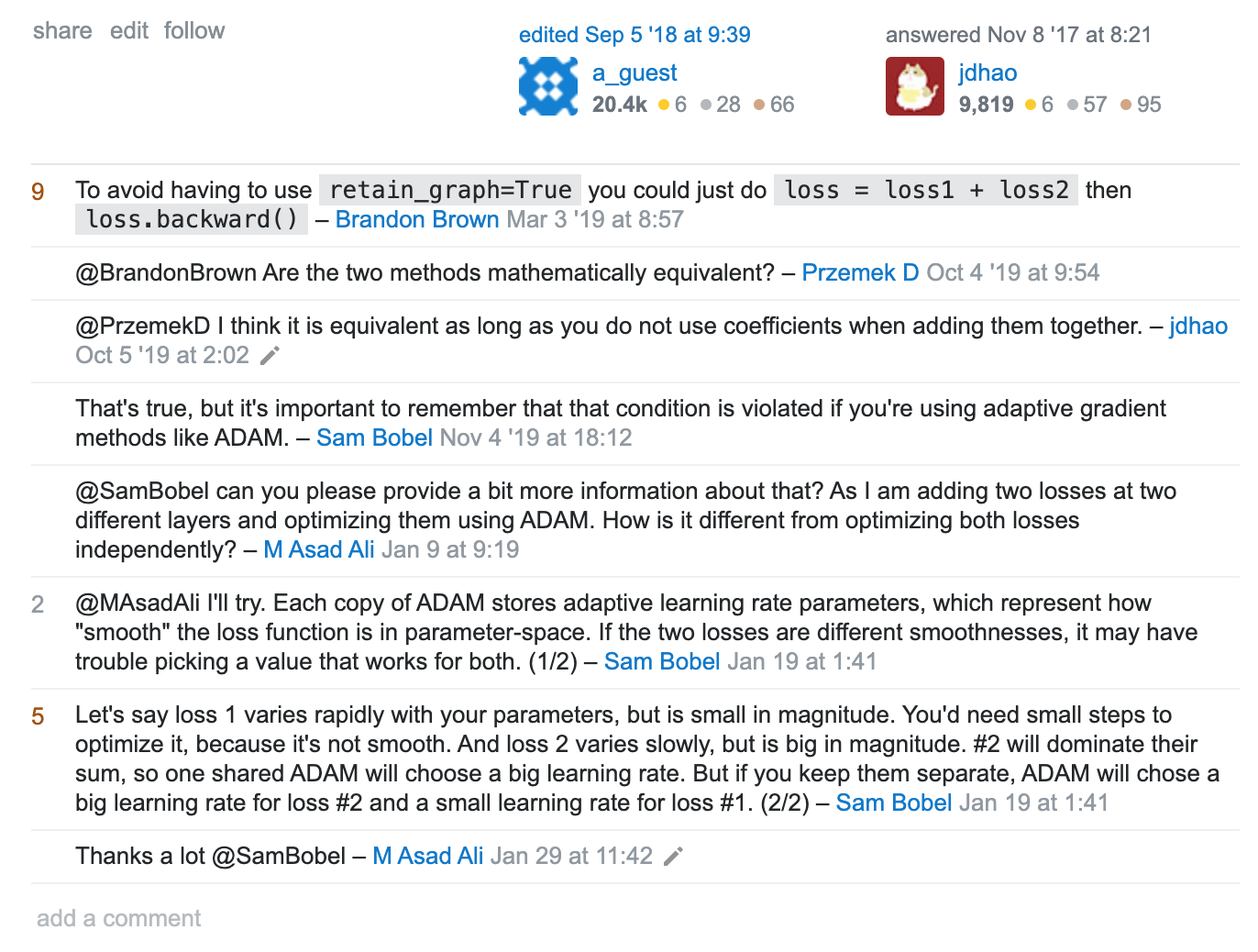
Do you agree with Sam Bobel?