Hello everyone. I have a conceptual question. I’m trying to understand the working of Faster and Mask RCNN. I’m working with two sizes of images (RGB), 1280x720 and 720x720, for two different tasks. These networks first’s block is the GeneralizedRCNNTransform module, that does normalization and resizing. The resize is defined by the parameters min_size and max_size. When I use batches of images of 1280x720, I keep the default values min_size=800 and max_size=1333, on the other hand I use min_size=800, max_size = 800 when I’m using images of 720x720. Checking the outcome of this module, I get images of 1344x768 and 800x800 respectively, and in both cases the network accepts these batches. It’s really weird to me that the network can process images of different sizes, and aspect ratios, because several CNN’s in other implementations need images of fixed sizes. My question is; How does the network do it? Is it because the network uses proposals regions and doesn’t need to flatten the output of the whole tensor of features? Or is something about the resizing that I’m missing?
The following sentences are from this post by Saurabh Bagalkar. This might help you.
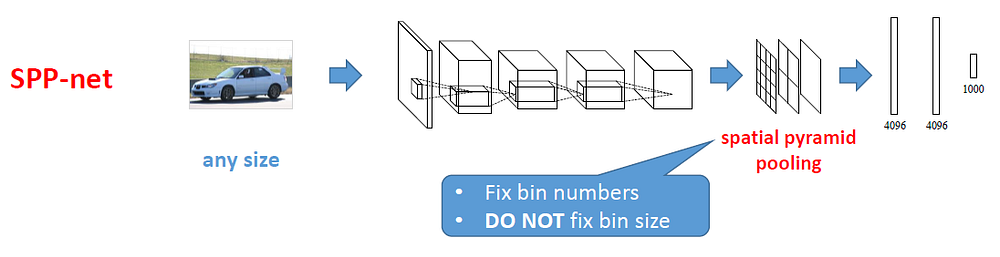
Need for Spatial Pyramid Pooling
But why do we have to do the spatial pyramid pooling in the first place? You see, CNNs, which have dense connection representations at deeper levels, traditionally require a fixed input size in accordance with the architecture used. For example, it is common practice to use 227 x 227 X 3 for AlexNet. So why do CNNs require a fixed image size? Let’s analyze this quote from the SPPNet paper:
In fact, convolutional layers do not require a fixed image size and can generate feature maps of any sizes. On the other hand, the fully-connected layers need to have fixed size/length input by their definition. Hence, the fixed size constraint comes only from the fully-connected layers, which exist at a deeper stage of the network.
The authors make a very important point that fully connected layers require a fixed image size. Why? As we know, backpropagation is always done with respect to weights and biases. In convolutional layers, these weights are nothing but the filters or feature maps. The number of feature maps is always independent of the image height and width and is decided a priori. Fully connected layers have a fixed length. If we have images of varying spatial dimensions while training, we cannot comply to a fixed flattened vector, because this will lead to dimension mismatch errors. To avoid this, we have to use fixed image dimensions. Resizing and cropping images is not always ideal because the recognition/classification accuracy can be compromised as a result of content and information loss or distortion.
The spatial bins that we use here (16, 4, 1) have sizes proportional to image size, so the number of bins is fixed regardless of image size. This means we get rid of the size constraint i.e no cropping and resizing of original images. This significantly increases efficiency because now we do not have to preprocess images in a fixed aspect ratio (i.e. fixed height and width) and will always get a fixed flattened vector regardless of what image size you pass in as input.