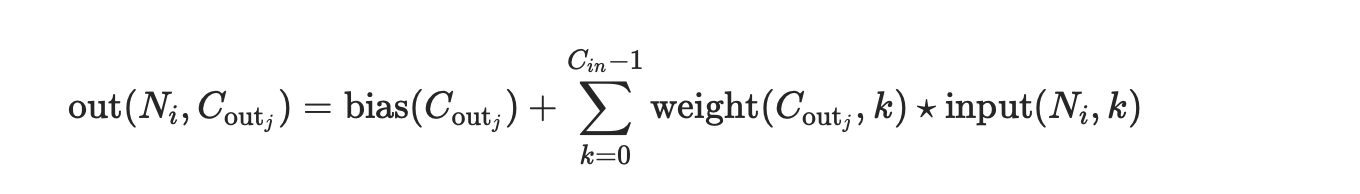I have:
print('\ninp', inp.min(), inp.mean(), inp.max())
print(inp)
out = self.conv1(inp)
print('\nout1', out.min(), out.mean(), out.max())
print(out)
quit()
My min, mean and max for my inp is: inp tensor(9.0060e-05) tensor(0.1357) tensor(2.4454)
For my output, I have: out1 tensor(4.8751, grad_fn=<MinBackward1>) tensor(21.8416, grad_fn=<MeanBackward0>) tensor(54.9332, grad_fn=<MaxBackward1>)
My self.conv1 is:
self.conv1 = torch.nn.Conv1d(
in_channels=161,
out_channels=161,
kernel_size=11,
stride=1,
padding=5)
self.conv1.weight.data = torch.zeros(self.conv1.weight.data.size())
self.conv1.weight.data[:, :, 5] = 1.0
self.conv1.bias.data = torch.zeros(self.conv1.bias.data.size())
So my weights look like: tensor([0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.])
So if I understand how convolution works, this should produce the same output. But it doesn’t.
What am I doing wrong? I realize that there’s some summing going on, but then how would I have an identity kernel?