I want to crop each cifar10 images half(0-15) and half(16-31) height.
32x32 -> 2x16x32
I can’t solve this with my code…
Because after crop like that, when I put the data in model, dataloder makes problem…
Thank you for your help.
I want to crop each cifar10 images half(0-15) and half(16-31) height.
32x32 -> 2x16x32
I can’t solve this with my code…
Because after crop like that, when I put the data in model, dataloder makes problem…
Thank you for your help.
Could you post the code you’ve used so far?
If should be possible to create these tensors in the __getitem__ of your Dataset.
Like this, I want to include crop function into transforms.compose but it didn’t work.
And this is what I tried, it works to crop height 1/2, but it is hard to apply to model train.
Because DataLoader do not support this logic…
If I can include height 1/2 crop function into transform compose, the problem might be solved I think.
Thank you for your kindness.
Could you try to concatenate both images in crop_half?
up = transforms...
down = transforms...
return torch.cat((up, down), dim=2)
PS: If you post code using three backticks ```, we could easily copy your code and debug it.
Also the search will be able to use your code so that others could easily find your solution to a similar problem. 
Thank you!!
If you need .ipynb file I can give you by email then send me mail (dnjscjf92@ajou.ac.kr)
Umm…
My purpose is after crop half the cifar10 image like 16x32, make two input up and down data sets, to put in each model input size is 16x32.
After put in these data to VGG16’s first layer, concat two feature map like before crop, and flow it as normal VGG16 model.
Your comment might be save me.
Thank you.
Under is my foolish code!!
import torch
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
from torchsummary import summary
from torchvision import datasets, transforms
import numpy as np
from tqdm import tqdm
import time
import os
import torch.backends.cudnn as cudnn
import matplotlib.pyplot as plt
# Loda data
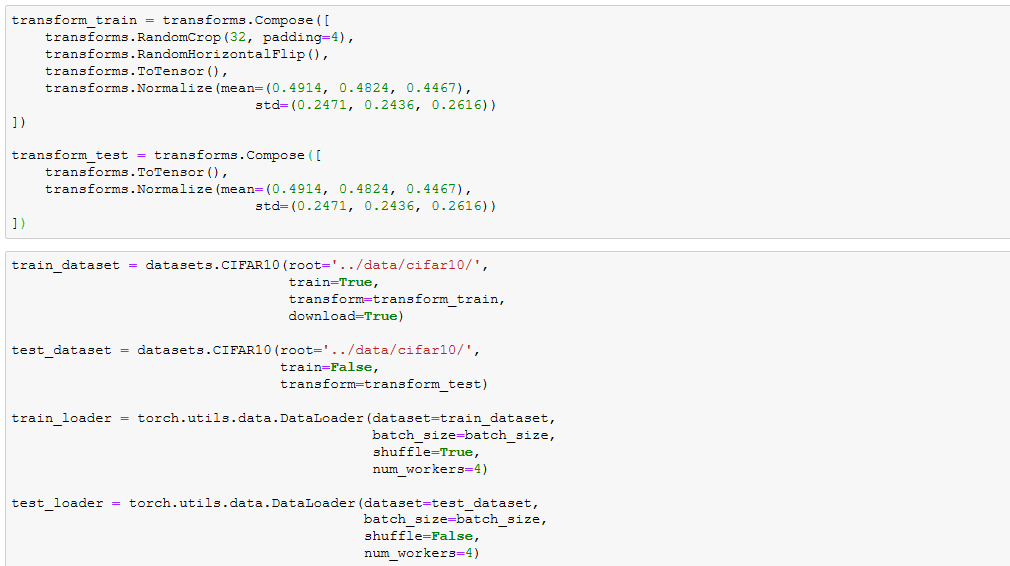
train_dataset = datasets.CIFAR10(root='../data/cifar10/',
train=True,
download=True)
test_dataset = datasets.CIFAR10(root='../data/cifar10/',
train=False)
#crop
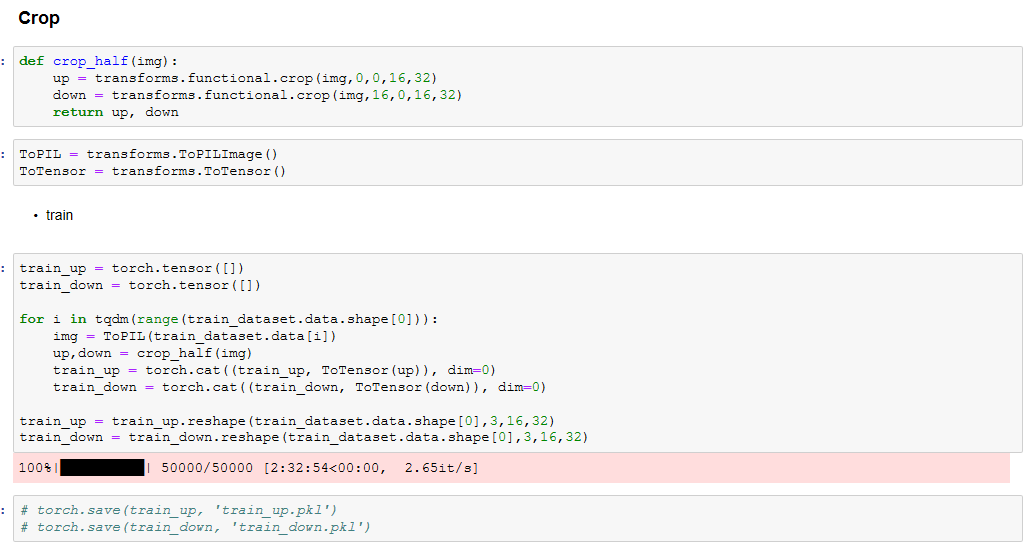
def crop_half(img):
up = transforms.functional.crop(img,0,0,16,32)
down = transforms.functional.crop(img,16,0,16,32)
return up, down
ToPIL = transforms.ToPILImage()
ToTensor = transforms.ToTensor()
#train
train_up = torch.tensor([])
train_down = torch.tensor([])
for i in tqdm(range(train_dataset.data.shape[0])):
img = ToPIL(train_dataset.data[i])
up,down = crop_half(img)
train_up = torch.cat((train_up, ToTensor(up)), dim=0)
train_down = torch.cat((train_down, ToTensor(down)), dim=0)
train_up = train_up.reshape(train_dataset.data.shape[0],3,16,32)
train_down = train_down.reshape(train_dataset.data.shape[0],3,16,32)
#test
test_up = torch.tensor([])
test_down = torch.tensor([])
for i in tqdm(range(test_dataset.data.shape[0])):
img = ToPIL(test_dataset.data[i])
up,down = crop_half(img)
test_up = torch.cat((test_up, ToTensor(up)), dim=0)
test_down = torch.cat((test_down, ToTensor(down)), dim=0)
test_up = test_up.reshape(test_dataset.data.shape[0],3,16,32)
test_down = test_down.reshape(test_dataset.data.shape[0],3,16,32)
#model
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
start_time = time.time()
batch_size = 128
learning_rate = 0.1
# 'head' means first layer with 16x32 cropped image data
class Vgg16_head(nn.Module):
def __init__(self, num_classes=10):
super(Vgg16_head, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
class Vgg16(nn.Module):
def __init__(self, num_classes=10):
super(Vgg16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Linear(2048, num_classes)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model_head = Vgg16_head()
optimizer = optim.SGD(model_head.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss().cuda()
model_head = nn.DataParallel(model_head)
cudnn.benchmark = True
model_head.cuda()
model = Vgg16()
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss().cuda()
model = nn.DataParallel(model)
cudnn.benchmark = True
model.cuda()
targets = torch.tensor(train_dataset.targets).reshape(-1,125)
def train_head(epoch):
# model_head.train()
model.train()
train_loss = 0
total = 0
correct = 0
for data_idx, (data, target) in enumerate(zip(train_up, targets)):
if torch.cuda.is_available():
data, target = Variable(data.cuda()), Variable(target.cuda())
else:
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.data
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += predicted.eq(target.data).cpu().sum()
if batch_idx % 10 == 0:
print('Epoch: {} | Batch: {} | Loss: ({:.4f}) | Acc: ({:.2f}%) ({}/{})'
.format(epoch, batch_idx, train_loss/(batch_idx+1), 100.*correct/total, correct, total))
def test():
model.eval()
test_loss = 0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(zip(test_up, targets)):
if torch.cuda.is_available():
data, target = Variable(data.cuda()), Variable(target.cuda())
else:
data, target = Variable(data), Variable(target)
outputs = model(data)
loss = criterion(outputs, target)
test_loss += loss.data
_, predicted = torch.max(outputs.data, 1)
total += target.size(0)
correct += predicted.eq(target.data).cpu().sum()
if batch_idx % 10 == 0:
print('TEST : Loss: ({:.4f}) | Acc: ({:.2f}%) ({}/{})'
.format(test_loss/(batch_idx+1), 100.*correct/total, correct, total))
# The last cell
# run model train
for epoch in range(0, 165):
if epoch < 80:
learning_rate = learning_rate
elif epoch < 120:
learning_rate = learning_rate * 0.1
else:
learning_rate = learning_rate * 0.01
for param_group in optimizer.param_groups:
param_group['learning_rate'] = learning_rate
train_head(epoch)
test()
# print("start_time", start_time)
print("--- Total %s seconds ---" % (time.time() - start_time))
(The last cell occur under error message)
RuntimeError Traceback (most recent call last)
<ipython-input-115-bdeec26048b8> in <module>
9 param_group['learning_rate'] = learning_rate
10
---> 11 train_head(epoch)
12 test()
13
<ipython-input-113-cb7193d6e59e> in train_head(epoch)
13
14 optimizer.zero_grad()
---> 15 output = model(data)
16 loss = criterion(output, target)
17 loss.backward()
~/.local/lib/python3.5/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/.local/lib/python3.5/site-packages/torch/nn/parallel/data_parallel.py in forward(self, *inputs, **kwargs)
139 inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids)
140 if len(self.device_ids) == 1:
--> 141 return self.module(*inputs[0], **kwargs[0])
142 replicas = self.replicate(self.module, self.device_ids[:len(inputs)])
143 outputs = self.parallel_apply(replicas, inputs, kwargs)
~/.local/lib/python3.5/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
<ipython-input-85-4b17a74fdecd> in forward(self, x)
32 x = self.features(x)
33 x = x.view(x.size(0), -1)
---> 34 x = self.classifier(x)
35 return x
~/.local/lib/python3.5/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs)
487 result = self._slow_forward(*input, **kwargs)
488 else:
--> 489 result = self.forward(*input, **kwargs)
490 for hook in self._forward_hooks.values():
491 hook_result = hook(self, input, result)
~/.local/lib/python3.5/site-packages/torch/nn/modules/linear.py in forward(self, input)
65 @weak_script_method
66 def forward(self, input):
---> 67 return F.linear(input, self.weight, self.bias)
68
69 def extra_repr(self):
~/.local/lib/python3.5/site-packages/torch/nn/functional.py in linear(input, weight, bias)
1350 if input.dim() == 2 and bias is not None:
1351 # fused op is marginally faster
-> 1352 ret = torch.addmm(torch.jit._unwrap_optional(bias), input, weight.t())
1353 else:
1354 output = input.matmul(weight.t())
RuntimeError: size mismatch, m1: [125 x 4096], m2: [2048 x 10] at /pytorch/aten/src/THC/generic/THCTensorMathBlas.cu:266
Currently you are cropping each image and append each crop to a new tensor.
To do so I would recommend to avoid concatenating the tensor in each iteration and just append the crops to a list and call torch.stack on it, as it will be much faster:
#train
train_up = []
train_down = []
for i in range(train_dataset.data.shape[0]):
img = ToPIL(train_dataset.data[i])
up,down = crop_half(img)
train_up.append(ToTensor(up))
train_down.append(ToTensor(down))
train_up = torch.stack(train_up)
train_down = torch.stack(train_down)
Once this is done, I would wrap these tensors in a custom Dataset and yield each the up and down crops for each sample:
class MyDataset(Dataset):
def __init__(self, data_up, data_down, targets):
self.data_up = data_up
self.data_down = data_down
self.targets = targets
def __getitem__(self, index):
up = self.data_up[index]
down = self.data_down[index]
y = self.targets[index]
return up, down, y
def __len__(self):
return len(self.data_up)
batch_size = 128
train_dataset = MyDataset(train_up, train_down, train_dataset.targets)
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True
)
Therefore I would just create a head and features layer in your VGG model, pass both crops separately through head, and concatenate the activations afterwards:
class Vgg16(nn.Module):
def __init__(self, num_classes=10):
super(Vgg16, self).__init__()
self.head = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.features = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Linear(2048, num_classes)
def forward(self, x_up, x_down):
x_up = self.head(x_up)
x_down = self.head(x_down)
x = torch.cat((x_up, x_down), dim=2)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
Note that Variables are deprecated since PyTorch 0.4.0 and also I would recommend using .to(device) instead of .cuda(), so I’ve rewritten your code to the new style:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = Vgg16()
model.to(device)
optimizer = optim.SGD(model.parameters(), lr=1e-3, momentum=0.9, weight_decay=1e-4)
criterion = nn.CrossEntropyLoss()
def train(epoch):
model.train()
train_loss = 0
total = 0
correct = 0
for batch_idx, (data_up, data_down, target) in enumerate(train_loader):
data_up, data_down, target = data_up.to(device), data_down.to(device), target.to(device)
optimizer.zero_grad()
output = model(data_up, data_down)
loss = criterion(output, target)
loss.backward()
optimizer.step()
train_loss += loss.data
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += predicted.eq(target.data).cpu().sum()
if batch_idx % 10 == 0:
print('Epoch: {} | Batch: {} | Loss: ({:.4f}) | Acc: ({:.2f}%) ({}/{})'
.format(epoch, batch_idx, train_loss/(batch_idx+1), 100.*correct/total, correct, total))
Your learning rate was a bit high with 0.1 so I lowered it also to 1e-3 so that your model started to learn.
@ptrblck
Wow… I touched…
You are so cool!! Thank you so much for your help!!
I didn’t check this code yet but I will keep going based with your help.
Thank you again^^.
Hey, @ptrblck !
Based your code with little custom edit, I solved problem!!
But there is something I cannot understand.
class Vgg16(nn.Module):
def __init__(self, num_classes=10):
super(Vgg16, self).__init__()
self.head = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.features = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Linear(2048, num_classes)
def forward(self, x_up, x_down):
x_up = self.head(x_up)
x_down = self.head(x_down)
x = torch.cat((x_up, x_down), dim=2)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
And how can I show the cropped & concatenated feature map using plt.imshow ?
Thank you so much again.
The current model should work as you’ve described in the sketch, i.e. both cropped inputs will be passed through the head layer, concatenated afterwards and passed through the rest of the model.
If you would like to visualize the cropped and concatenated feature maps, you could add them to the return statement:
def forward(self, x_up, x_down, return_features=False):
x_up = self.head(x_up)
x_down = self.head(x_down)
x_cat = torch.cat((x_up, x_down), dim=2)
x = self.features(x_cat)
x = x.view(x.size(0), -1)
x = self.classifier(x)
if return_features:
return x, x_up, x_down, x_cat
else:
return x
Now you could just use return_features=True, which will give you the intermediate activations:
output, act_up, act_down, act_concat = model(x_up, x_down, return_features=True)
I will check this!
Thank you!! You are gorgeous!!
@ptrblck
Hi^^.
It’e me again.
Now I’m trying to find out which is influencing to the lower performance
between cropped image and model architecture.
So what I want to try is
“train original(uncropped) Vgg16 and with this weight test with cropped images”.
How can I save the trained original vgg weight
and load this to cropped image test in my cropped model?
Thank you.
I assume the model architecture does not change, but only the forward definition.
If that’s the case, you could just save the state_dict using the Serialization semantics.
You should be able to load the state_dict in both models, as long as all submodules are equal.
torch.save(model.state_dict(), "./weight/vgg16_baseline.pth")
After save original vgg weight,
model = myVgg16()
model.load_state_dict(torch.load("./weight/vgg16_baseline.pth"))
This code makes under error.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-12-6ceaad033204> in <module>
1 model = myVgg16()
----> 2 model.load_state_dict(torch.load("./weight/vgg16_baseline.pth"))
~/.local/lib/python3.5/site-packages/torch/nn/modules/module.py in load_state_dict(self, state_dict, strict)
767 if len(error_msgs) > 0:
768 raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(
--> 769 self.__class__.__name__, "\n\t".join(error_msgs)))
770
771 def _named_members(self, get_members_fn, prefix='', recurse=True):
RuntimeError: Error(s) in loading state_dict for myVgg16:
Missing key(s) in state_dict: "head.0.weight", "head.0.bias", "head.1.running_mean", "head.1.running_var", "head.1.weight", "head.1.bias", "features.0.weight", "features.0.bias", "features.1.running_mean", "features.1.running_var", "features.1.weight", "features.1.bias", "features.4.weight", "features.4.bias", "features.5.running_mean", "features.5.running_var", "features.5.weight", "features.5.bias", "features.7.weight", "features.7.bias", "features.8.running_mean", "features.8.running_var", "features.8.weight", "features.8.bias", "features.11.weight", "features.11.bias", "features.12.running_mean", "features.12.running_var", "features.12.weight", "features.12.bias", "features.14.weight", "features.14.bias", "features.15.running_mean", "features.15.running_var", "features.15.weight", "features.15.bias", "features.17.weight", "features.17.bias", "features.18.running_mean", "features.18.running_var", "features.18.weight", "features.18.bias", "features.21.weight", "features.21.bias", "features.22.running_mean", "features.22.running_var", "features.22.weight", "features.22.bias", "features.24.weight", "features.24.bias", "features.25.running_mean", "features.25.running_var", "features.25.weight", "features.25.bias", "features.27.weight", "features.27.bias", "features.28.running_mean", "features.28.running_var", "features.28.weight", "features.28.bias", "features.31.weight", "features.31.bias", "features.32.running_mean", "features.32.running_var", "features.32.weight", "features.32.bias", "features.34.weight", "features.34.bias", "features.35.running_mean", "features.35.running_var", "features.35.weight", "features.35.bias", "features.37.weight", "features.37.bias", "features.38.running_mean", "features.38.running_var", "features.38.weight", "features.38.bias", "classifier.0.weight", "classifier.0.bias", "classifier.1.weight", "classifier.1.bias", "classifier.2.weight", "classifier.2.bias".
Unexpected key(s) in state_dict: "module.features.0.weight", "module.features.0.bias", "module.features.1.weight", "module.features.1.bias", "module.features.1.running_mean", "module.features.1.running_var", "module.features.1.num_batches_tracked", "module.features.3.weight", "module.features.3.bias", "module.features.4.weight", "module.features.4.bias", "module.features.4.running_mean", "module.features.4.running_var", "module.features.4.num_batches_tracked", "module.features.7.weight", "module.features.7.bias", "module.features.8.weight", "module.features.8.bias", "module.features.8.running_mean", "module.features.8.running_var", "module.features.8.num_batches_tracked", "module.features.10.weight", "module.features.10.bias", "module.features.11.weight", "module.features.11.bias", "module.features.11.running_mean", "module.features.11.running_var", "module.features.11.num_batches_tracked", "module.features.14.weight", "module.features.14.bias", "module.features.15.weight", "module.features.15.bias", "module.features.15.running_mean", "module.features.15.running_var", "module.features.15.num_batches_tracked", "module.features.17.weight", "module.features.17.bias", "module.features.18.weight", "module.features.18.bias", "module.features.18.running_mean", "module.features.18.running_var", "module.features.18.num_batches_tracked", "module.features.20.weight", "module.features.20.bias", "module.features.21.weight", "module.features.21.bias", "module.features.21.running_mean", "module.features.21.running_var", "module.features.21.num_batches_tracked", "module.features.24.weight", "module.features.24.bias", "module.features.25.weight", "module.features.25.bias", "module.features.25.running_mean", "module.features.25.running_var", "module.features.25.num_batches_tracked", "module.features.27.weight", "module.features.27.bias", "module.features.28.weight", "module.features.28.bias", "module.features.28.running_mean", "module.features.28.running_var", "module.features.28.num_batches_tracked", "module.features.30.weight", "module.features.30.bias", "module.features.31.weight", "module.features.31.bias", "module.features.31.running_mean", "module.features.31.running_var", "module.features.31.num_batches_tracked", "module.features.34.weight", "module.features.34.bias", "module.features.35.weight", "module.features.35.bias", "module.features.35.running_mean", "module.features.35.running_var", "module.features.35.num_batches_tracked", "module.features.37.weight", "module.features.37.bias", "module.features.38.weight", "module.features.38.bias", "module.features.38.running_mean", "module.features.38.running_var", "module.features.38.num_batches_tracked", "module.features.40.weight", "module.features.40.bias", "module.features.41.weight", "module.features.41.bias", "module.features.41.running_mean", "module.features.41.running_var", "module.features.41.num_batches_tracked", "module.classifier.0.weight", "module.classifier.0.bias", "module.classifier.1.weight", "module.classifier.1.bias", "module.classifier.2.weight", "module.classifier.2.bias".
Is this because the different head architecture?
Umm… then how can Ioad the weight?
How did you define the original model? You should also use myVGG16 and adapt the forward method to just use the head once.
class Vgg16(nn.Module):
def __init__(self, num_classes=10):
super(Vgg16, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512),
nn.Linear(512, 512),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
Above is original Vgg16
and under is myVgg16 which is you hinted for me.
class myVgg16(nn.Module):
def __init__(self, num_classes=10):
super(myVgg16, self).__init__()
self.head = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
)
self.features = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512),
nn.Linear(512, 512),
nn.Linear(512, num_classes)
)
def forward(self, x_up, x_down):
x_up = self.head(x_up)
x_down = self.head(x_down)
x = torch.cat((x_up, x_down), dim=2)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
You could use the same modules and just derive the “headed” version using a basic vgg16 implementation.
Here is a small example:
class myVgg16(nn.Module):
def __init__(self, num_classes=10):
super(myVgg16, self).__init__()
self.head = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
)
self.features = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512),
nn.Linear(512, 512),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.head(x)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
class myVgg16Headed(myVgg16):
def __init__(self, num_classes=10):
super(myVgg16Headed, self).__init__(num_classes)
def forward(self, x_up, x_down):
x_up = self.head(x_up)
x_down = self.head(x_down)
x = torch.cat((x_up, x_down), dim=2)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model = myVgg16()
model_headed = myVgg16Headed()
torch.save(model.state_dict(), 'tmp.pt')
model_headed.load_state_dict(torch.load('tmp.pt'))
Oh! I think I catched your idea!!
I will try it myself.
Thank you so much.
Hmm… it doesn’t solve the error.
Please look at my effort.
First, I trained Vgg16 (original) model.
class Vgg16(nn.Module):
def __init__(self, num_classes=10):
super(Vgg16, self).__init__()
self.head = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
)
self.features = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(64, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.Conv2d(128, 128, kernel_size=3, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(128, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(256, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.Conv2d(512, 512, kernel_size=3, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(True),
nn.MaxPool2d(kernel_size=2, stride=2),
)
self.classifier = nn.Sequential(
nn.Linear(512, 512),
nn.Linear(512, 512),
nn.Linear(512, num_classes)
)
def forward(self, x):
x = self.head(x)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
After run and train, saved weight like this.
torch.save(model.state_dict(), "./weight/vgg16_baseline.pth")
Second, I made myVgg16 (cropped) model.
(Here is the point, I used the same code to make Vgg16 and myVgg16 model. It’s just have different class name, is this right?)
Third, I made myVgg16Headed
class myVgg16Headed(myVgg16):
def __init__(self, num_classes=10):
super(myVgg16Headed, self).__init__(num_classes)
def forward(self, x_up, x_down):
x_up = self.head(x_up)
x_down = self.head(x_down)
x = torch.cat((x_up, x_down), dim=2)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
model_headed = myVgg16Headed()
(above code make myVgg16 too automatically…?)
model_headed.load_state_dict(torch.load('./weight/vgg16_baseline.pth'))
But the same error is occurred.
I’m not sure to understand it completely, but I think you would just need two models.
One using a single input and the other one using the cropped inputs, is that correct?
If so, you should just create the two models given in my last example, i.e. myVgg16 and myVgg16Headed.
Oh, with your help I solved problem finally.
model_headed = myVgg16Headed()
model_headed = nn.DataParallel(model_headed)
model_headed.load_state_dict(torch.load('./weight/vgg16_baseline.wts'))
In this cell, model_headed = nn.DataParallel(model_headed) solved the error.
And I have one more question about your code.
class myVgg16Headed(myVgg16):
def __init__(self, num_classes=10):
super(myVgg16Headed, self).__init__(num_classes)
def forward(self, x_up, x_down):
x_up = self.head(x_up)
x_down = self.head(x_down)
x = torch.cat((x_up, x_down), dim=2)
x = self.features(x)
x = x.view(x.size(0), -1)
x = self.classifier(x)
return x
Above code means that class myVgg16Headed(myVgg16) overridemyVgg16’s def forward ??