I want to have a CNN architecture with the below pipeline:
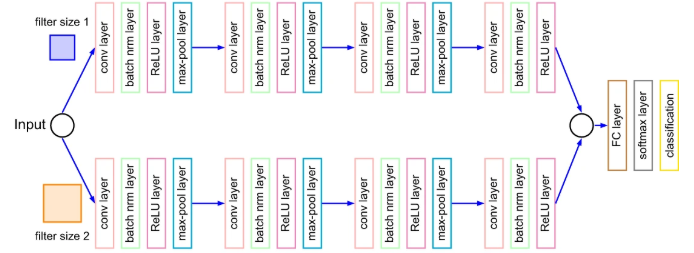
I’ve done normal CNN using PyTorch before. Can someone please suggest if there’s a feature in PyTorch that let’s me easily split as above?
Thanks so much in advance.
@ptrblck Please help ![]()
I want to have a CNN architecture with the below pipeline:
I’ve done normal CNN using PyTorch before. Can someone please suggest if there’s a feature in PyTorch that let’s me easily split as above?
Thanks so much in advance.
@ptrblck Please help ![]()
Hi,
If you have two cnns, you can simply do:
inp = # Your input
out1 = cnn1(inp)
out2 = cnn2(inp)
full_out = torch.cat([out1, ou2], dim=1) # dim=1 is the channel dimension for 2D images
full_out = full_out.view(full_out.size(0), -1) # Linearize for the FC
res = fc(full_out)
Does that work for you?
It will back propagate automatically. Nothing special needs to be done:
loss = crit(res, label)
loss.backward()
Then it’s your choice to have one optimizer for both nets, or one per net.
Thank you & I Assume it’s like this
optimizer = optim.SGD([p for p in model1.parameters()] +
[p for p in model2.parameters()]),
lr=0.001, momentum=0.9))
if you want both of them in the same optimizer yes.
The optimizer you defined seems only contain the parameters of Conv layers, what about the FC layers?
Hi,
I wonder if the two CNN are running parallelly. If they run sequentially, it could be inefficient.
Depends on how you implement it 
But in general, each one use all the parallelism available on the current machine by default. So you won’t get any benefit by running the two in parallel on that machine as they will fight for resources.
What is the parallelism? So if I have multiple CNN branches and each one runs independently, I only need to write them down one by one and need not tell PyTorch these CNNs can run parallelly in some way?
What I mean is that even simple ops like one conv will already be parallelized if it is big enough.
I see. My concern is regarding small conv. I heard that if we compare the runtimes of a big Conv layer and a series of cascaded small Conv layers, we will find that the cascaded small Conv layers takes more times to run even if the two settings have the same number of floating point operations. This is because small Conv layers cannot make full use of the GPU.
So I wonder if PyTorch has a mechanism to parallelize the small Conv layers that runs independently to accelerate it.
The problem is that the GPU itself is not built to run independent tasks in parallel. So you won’t be able to get the same speed with many small ops as with a single big one.
If you run on CPU, you can use multithreading as you would do for any workload to parallelize your execution.