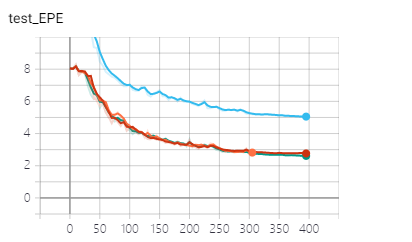
When I used Distributed dataparallel to replace dataparallel,the result of the validation set becomes very poor, as in the case of overfitting. I used 4 GPUs, one process per GPU, keeping the learning rate and batchsize unchanged.The following is all the code related to DPP:
dist.init_process_group(backend='nccl')
torch.cuda.set_device(args.local_rank)
device = torch.device("cuda", args.local_rank)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_set)
train_loader = torch.utils.data.DataLoader(
train_set, batch_size=args.batch_size,
num_workers=args.workers,sampler=train_sampler, pin_memory=True, shuffle=(train_sampler is None))
val_sampler = torch.utils.data.distributed.DistributedSampler(val_set)
val_loader = torch.utils.data.DataLoader(
val_set, batch_size=args.batch_size,
num_workers=args.workers, pin_memory=True, shuffle=False,sampler=val_sampler)
model = models.__dict__[args.arch](network_data).to(device)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank])
cudnn.benchmark = True
for epoch in tqdm(range(args.start_epoch, args.epochs)):
# train for one epoch
train_sampler.set_epoch(epoch)
train_loss=train(......)
dist.reduce(train_loss, 0, op=dist.ReduceOp.SUM)
print(train_loss/nb_gpus)
test_loss=validate(.....)
dist.reduce(test_loss, 0, op=dist.ReduceOp.SUM)
print(test_loss/nb_gpus)
If each DDP (DistributedDataParallel) process is using the same batch size as you passed to DataParallel, then I think you need to divide the reduced loss by world_size. Otherwise, you are summing together losses from world_size batches.
Another thing is that batch size and learning rate might need to change when switched to DDP. Check out the discussions below:
Thanks for your answer,it helped me a lot.
One conclusion I got from these materials is that I should set torch.utils.data.DataLoader(batch_size=args.batch_size/world_size)
lr still be 1xlr.
Is this correct?
Yes, this should let the DDP gang collectively process the same number of samples compared to the single process case. But it may or may not stay mathematically equivalent due to the loss function. DDP is taking average of grads across processes. So if the loss function is calculating sum loss of all samples or if (loss(x) + loss(y)) / 2 != loss([x, y]) / 2, it won’t be mathematically equivalent. Hence, it might take some efforts to optimizer the lr and batch size when using DDP.
No, you don’t need to manually average the loss. When using DDP, losses are local to every process, and DDP will automatically average gradients for all parameters using AllReduce communication.
My loss function is defined as follows: loss = torch.norm(target_flow - input_flow, 2, 1)/batch_size
The batch_size here is the per-process input batch size, right?
Yes,it’s per-process batch_size.
In fact, I think the problem is basically solved after dividing Batchsize by ngpus (although performance is still slightly behind DP, but this should be a tuning problem)
Thank you for your help. Best wishes!
hi @111344 ,I am using ddp pytorch for fine tunning my model. I am wondering how I can save the average of loss function from all gpus for showing the loss graph. when I printing the loss in the code, it shows me three losses from 3 gpus which make sense. but for graph I need to reduce the loss is the following code correct to apply? is the definition of “avg_train_loss_reduced” correct? many thanks for your feedback. or can you share what did you applied for getting teh graphs?
model = copy.deepcopy(model_or)
model=model.to(gpu_id)
model = DDP(model, device_ids=[gpu_id])
print("gpu_id",gpu_id)
# ========================================
# Training
# ========================================
for epoch_i in range(0, total_epochs):
print("")
print('======== Epoch {:} / {:} ========'.format(epoch_i + 1, total_epochs))
print('Training...')
##########################################
train_loader.sampler.set_epoch(epoch_i)
b_sz = len(next(iter(train_loader))[0])
print(f"[GPU{gpu_id}] Epoch {epoch_i} | Batchsize: {b_sz} | Steps: {len(train_loader)}")
train_loader.sampler.set_epoch(epoch_i)
##########################################
total_train_loss = 0
model.train()
for step, batch in enumerate(train_loader):
print("len(train_loader)",len(train_loader))
#################################
b_input_ids = batch[0].to(gpu_id,non_blocking=True)
b_labels = batch[0].to(gpu_id,non_blocking=True)
b_masks = batch[1].to(gpu_id,non_blocking=True)
#################################
optimizer.zero_grad()
outputs = model( b_input_ids,
labels=b_labels,
attention_mask = b_masks,
token_type_ids=None
)
loss = outputs[0]
batch_loss = loss.item()
total_train_loss += batch_loss
loss.backward()
optimizer.step()
scheduler.step()
# Calculate the average loss over all of the batches.
avg_train_loss = total_train_loss / len(train_loader)
## reduce the average loss from 3 gpus and get sum
dist.reduce(avg_train_loss, 0, op=dist.ReduceOp.SUM)
### devide by 3 because I used 3 gpus
avg_train_loss_reduced=avg_train_loss/3
Path_3=pt_save_directory+'/'+'avg_train_loss_reduced='+str(gpu_id)+".csv"
torch.save(avg_train_loss_reduced,Path_3)