I have some questions that prevent me from understanding PyTorch completely. They relate to how a Computation Graph is created and freed? For example, if I have this following piece of code:
import torch
for i in range(100):
a = torch.autograd.Variable(torch.randn(2, 3).cuda(), requires_grad=True)
y = torch.sum(a)
y.backward()
Does it mean that each time I run the code in a loop, it will create a completely new computation graph and the graph from the previous loop is freed from buffer?
If I call y.backward() like above, will the computation graph within that loop be freed from buffer?
If the graph is not freed, can I treat it as a static computation graph and do something like the code below?
Code:
import torch
# a like a placeholder
a = torch.autograd.Variable(torch.randn(2, 3).cuda(), requires_grad=True)
y = torch.sum(a)
for i in range(100):
a.data = torch.randn(2, 3).cuda() # Only modify its data
y.forward() # Call a forward over y (computed using pre-built graph)
y.backward() # Backward on built graph
@smth
Thanks for your explanation, I have one more question, if I add retain_graph=True in the following code, will all intermediary results in 100 graph exist in memory, or previous 99 graphs are freed and only the last graph exist in memory?
import torch
for i in range(100):
a = torch.autograd.Variable(torch.randn(2, 3).cuda(), requires_grad=True)
y = torch.sum(a)
y.backward(retain_graph=True)
Im confused, what exactly is the operation that frees up the graph? Is it because we create a new variable with requires_grad=True or what is it that creates a new computation graph? @smth
the operation that frees up the graph is variable scoping in python. The variables in the for loop scope go out of scope in the next iteration of the loop
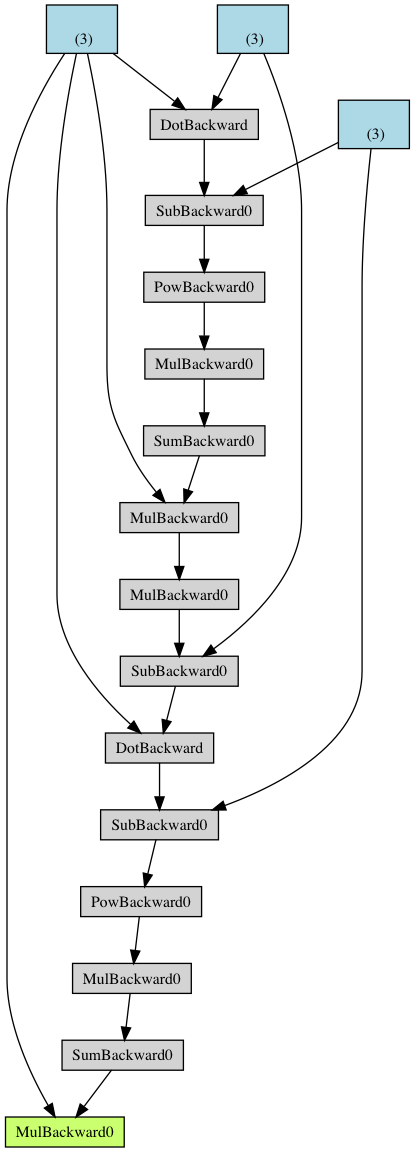
Hi, I think that if a variable is being updated within the loop with a value, for which the computational graph was retained before, then the computational graph is expanding on each iterations. E.g. for some A, b and u = tensors which require grad:
def f(A, b, u):
r = A@u - b
return (r**2).sum()
for k in range(5):
f_eval = f(A, input_b, y)
grad = torch.autograd.grad(f_eval, y, create_graph=True)[0]
y.grad = grad
y = y - 0.001*y.grad
make_dot(grad)
In general, what percentage of forward-backward combined time is spent reforming the computation graph? It seems like a trivial optimization to simply save whatever graph object is formed between forward passes if the underlying computation graph is in fact static. If this is possible, there’s no reason why static computation graph approaches need lazy execution (which is what makes Tensorflow a pain). For a static graph, the computation graph could be formed on the first forward pass (no lazy execution) and then simply saved. I feel like few applications actually use dynamic computation graphs (i.e. where different functions are run in different situations) and instead are all essentially static graphs that could benefit from this.
This was basically done using tracing. However, the current way is to use torch.jit.script, as it will also track the control flow.
Really? I have the feeling that especially due to the growth of NLP models the control flow capturing is getting even more important.
Which models have you compared from which domain?
I’m just referring to most typical feedforward ML models (like many models in computer vision, e.g. AlexNet, ResNet) where the computation graphs are set by the architecture. I see your point though (although I feel like even recurrent models don’t necessarily require full dynamic computation graph tracking and could just “copy-and-paste” whatever computation graph building operation occurs for one recursion for each recursion). Full disclosure, I’m not terribly familiar with the implementation of autograd.
The big question is how much of a performance hit is given by dynamic graph construction.