For example, if I need to implement a matchnet, which requires two samples to pass through two models with shared weights, and compute the loss with the two outputs. If I need to try this with pytorch, what is the correct way to do this ?
I am thinking that maybe I could run forward path two times with the two input samples and then compute the loss and run backward path. But I do not if this is the correct option, since, for some modules, the backward options need the forward path input, and if I run forward two times with two different inputs, the backward process is likely to be disturbed. So what is the good way to do this ?
Depending on what you want. The way of implementing a Siamese network which is a network with shared weights is defining one network but calling it twice.
If you check the graphical model you would be creating two nodes in parallel, one pet calling.
This may not to be what you want to do, since you may want pytorch to compute both independently. Then, you should stack both in a batch and did the forward pass and to split them
Just to make sure, could I simply implement forward() and backward() two times with the two inputs separately and then run the optim.step() once to update the two paths?
The problem is that the output of the model comes from the same input and model, while the loss has some weight tensor in it which is expected to be shared with the two outputs out1 and out2.
What is the good way to do this, please ?
But the way you are describing in that snippet is perfectly good. You have a model with one input, one output. You can sum losses and you are applying backward once. Then what’s the problem?
If you run a model() twice and you backpropagate you will backpropagate the average gradients. If you stack in a single batch both inputs and backpropagate you will backpropagate average error. As @zeakey said, if you run backward without zero grad you will accumulate gradients.
But I guess the backward path is sort of dependent on some of the middle-result of the forward path. If I run forward path twice, the middle result of the first path will be covered. Therefore, it seems that two forward paths and one backward may not be a good idea.
Not really. Running 2FW/1BW generates a siamese network which is very common and studied. For models which shares weights this is the most typical architecture.
But in fact differences among what we are commenting are very case-dependent.
Think that if you stack both inputs into a single one before feeding (by stacking them), you are computing a single output. When the error gets backpropagated it will be taken into account as if it were the same error for both input samples since.
Using 2FW/1BW is equivalent to get error for input one, error for input two and then average them (since you are sharing weights)
Which one works better? difficult to say without testing
I don’t know the exact behavior of using 2FW/2BW. Accumulating gradients sounds like they may cancel among them. This way would be closer to stacking into a single batch since you get a representation of the error which backpropagates exactly the same for both samples.
Nevertheless, as I was saying, the differences among these ways are slight, you can try them to see which one works better in your case of try to ask to the authors which one are they following
support there is a linear layer: y=xW, the gradient of W might be computed like this: dy/dW = x.t(). This means that the backward path need the exact input value. So when I compute forward with x1 and then with x2, won’t the gradient be computed merely with x2 since x1 is covered ? Or if pytorch will store both x1 and x2, why will the memory not be used up when doing the inference (which executes merely forward path computation many times) ?
Well it’s a difficult question. Maybe @albanD or @ptrblck can clarify it.
If I had have to give you an answer I’d say that:
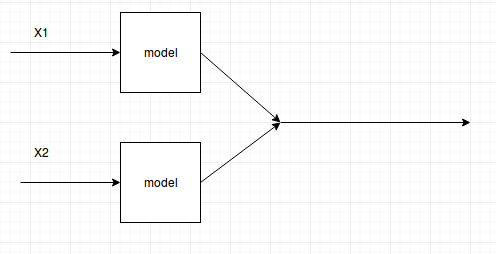
When you compute forward for x1 and then forward for x2, you are creating a joint in the computational graph like this:
According to the theory of siamese networks you should get gradients for both and then update the model with averaged gradients.
This proper follows the statements in which you require to have both gradients.
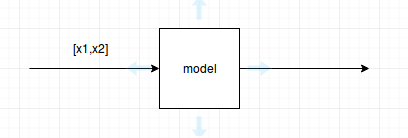
In case you stack them into a single batch you would have this graph
Which would compute gradients of the error of both samples as a batch. Therefore it does not match what you want to do.
The last case, in which you accumulate gradients would have a similar representation with neither match your case.
I think your main worry is what will happen if you forward multiple times on the same nn.Module.
Pytorch will create and keep around all the necessary Tensors to be able to compute the gradients corresponding to what you did in the forward. In particular, if you forward twice the same Linear layer, it will keep around both inputs and weights to be able to compute all the gradients.
This has a quite large memory impact. You can check for example the memory usage just after creating/loading your model and just after doing one forward pass. You will see that the memory consumption increase significantly (more than double in most cases) after the first forward pass. But this is expected and you can’t really get around it (see torch.utils.checkpoint if you have memory issues )
 )
)