So, basically i have been watching a specific project for old captcha solving, and i would like to know how he trained it (because he did not say how he made it)
his input is:
Class (lets say, the captcha wants a grape, you set that as the input so the model know what to check for, look examples below)
Pictures (the captcha gives 4 slightly deformed pictures and one of them is a grape) (it’s pixelart)
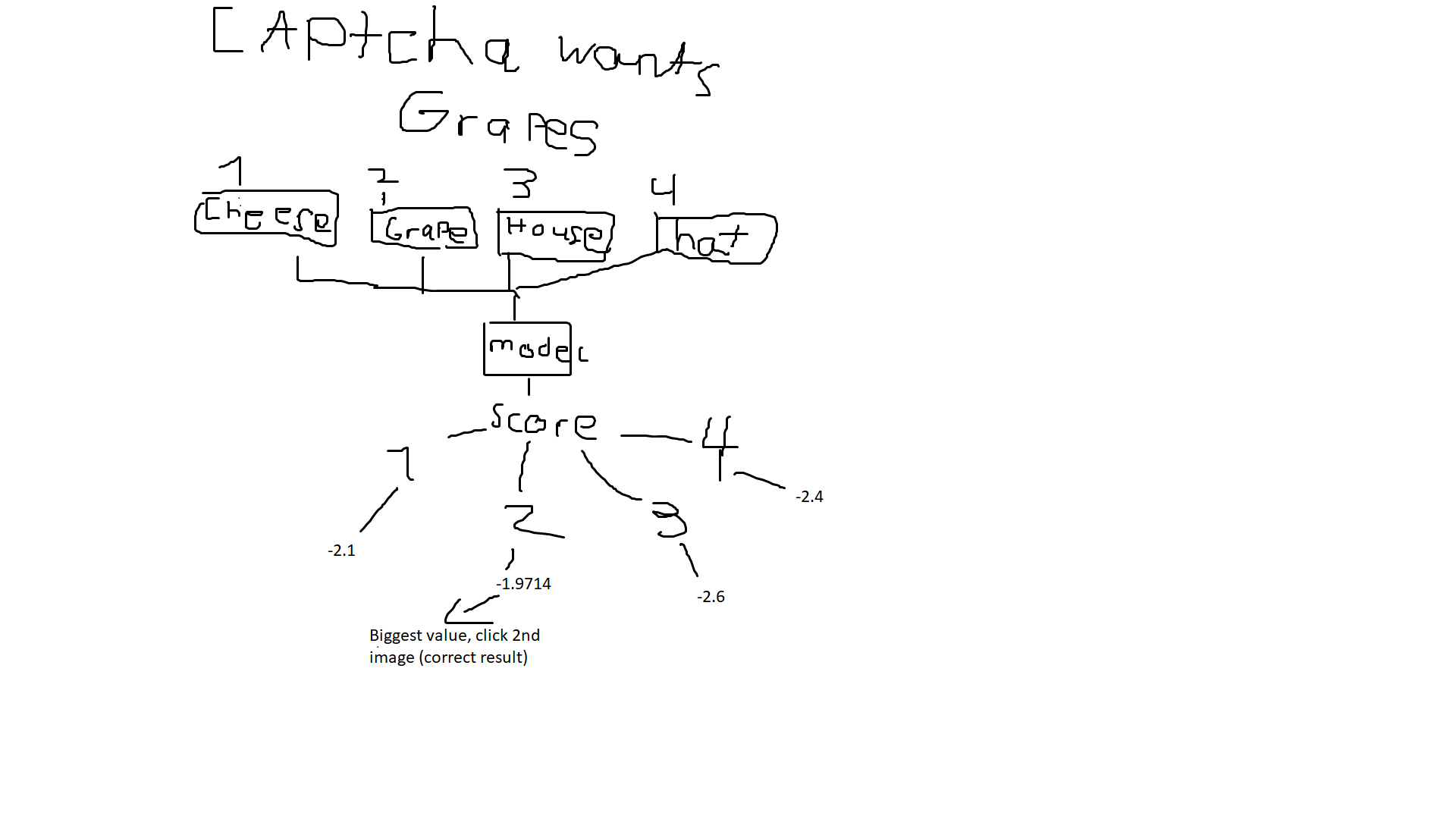
How did he do that?
his code:
verifier=
import numpy as np
import torch
import torch.nn as nn
import utils
from model.resnet import resnet34
import torchvision.transforms as transforms
import os
import time
from torch.autograd import Variable
from PIL import Image
model_dir = './output/model.pt'
DEVICE = torch.device('cpu')
NUM_classes = 40
CLASS_NAMES = ["banana", "book", "bread", "candy cane", "candy corn", "cannon", "carrot", "cheese", "cherry", "chest piece", "clock", "diamond",
"egg", "fire", "fish", "frog", "ghost", "grapes", "gun", "hat", "helmet", "house", "key", "lemon", "mushroom", "necklace", "pear",
"pepper", "pie", "piece of meat", "pineapple", "pretzel", "pumpkin", "rose", "strawberry", "treasure chest", "watermelon", "empty bottle", "orange", "crown"]
def preprocessing_image(img, transform):
if len(img.split()) == 4:
r, g, b, a = img.split()
elif len(img.split()) == 3:
r, g, b = img.split()
img = Image.merge("RGB", (r, g, b))
img = img.resize((224, 224), Image.ANTIALIAS)
img = transform(img)
img = img.view(-1, 3, 224, 224)
return img
def simmmover(image_path, item):
real = utils.getLabelValue(item)
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
model = resnet34(pretrained=False, num_classes=NUM_classes)
model.load_state_dict(torch.load(model_dir))
model = model.to(DEVICE)
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
model.eval()
img1 = preprocessing_image(Image.open(os.path.join(image_path, 'img1.png')), transformations)
img2 = preprocessing_image(Image.open(os.path.join(image_path, 'img2.png')), transformations)
img3 = preprocessing_image(Image.open(os.path.join(image_path, 'img3.png')), transformations)
img4 = preprocessing_image(Image.open(os.path.join(image_path, 'img4.png')), transformations)
#Looks for the most accurate result, given its name & pictures if the picture matches with the name -> result
img1, img2, img3, img4 = img1.to(DEVICE), img2.to(DEVICE), img3.to(DEVICE), img4.to(DEVICE)
prediction1 = model(img1).squeeze()
prediction2 = model(img2).squeeze()
prediction3 = model(img3).squeeze()
prediction4 = model(img4).squeeze()
print(prediction1[real])
print(prediction2[real])
print(prediction3[real])
print(prediction4[real])
#_, predicted1 = torch.max(prediction1, 1)
#_, predicted2 = torch.max(prediction2, 1)
#_, predicted3 = torch.max(prediction3, 1)
#_, predicted4 = torch.max(prediction4, 1)
_, predicted = torch.max(torch.tensor([prediction1[real], prediction2[real], prediction3[real], prediction4[real]]), 0)
result = 'img' + str(predicted.item()+1)
return result
example1=
element = driver.find_element(By.CSS_SELECTOR, ".text-2xl")
item = element.text.lower()
prediction = verifier.simmmover("./temporary", item)
if prediction == 'img1':
es1.click()
elif prediction == 'img2':
es2.click()
elif prediction == 'img3':
es3.click()
elif prediction == 'img4':
es4.click()
time.sleep(3)
example 2=
item = "grapes"
prediction = verifier_test.simmmover("./temporary", item)
print(prediction)
(temporary = the images from the given captcha)