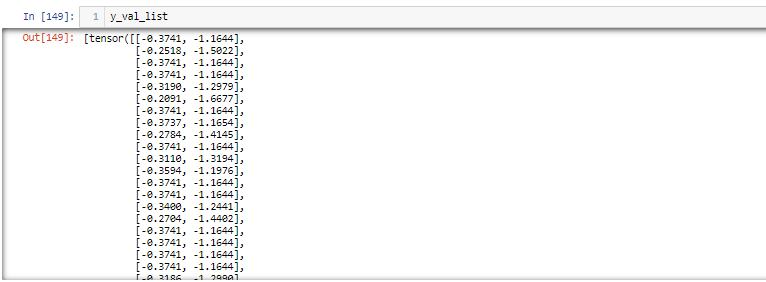
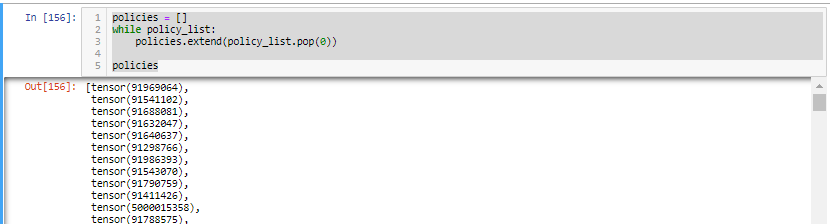
Hello.
I have the following model schema where one set of photos go through an encoder, another set of photos go through an encoder and both get concatenated with a tabular data set for a final model to predict a binary target.
How do I average the features of the image encoders? I want to average by ID within each model. See schema below.
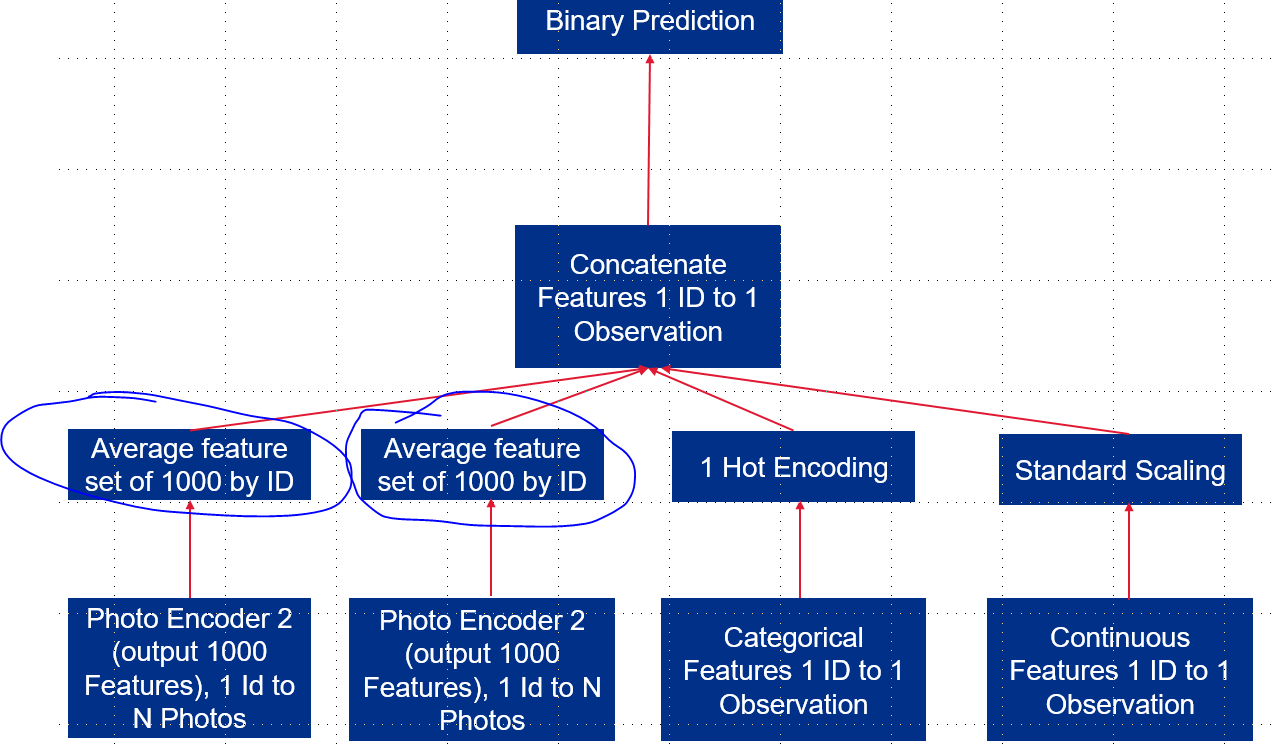
There are 1 to 5 photos per ID. There is an ID in each image model and tabular data set.
My data class returns the image, label and ID (called policy)…see below code for that class:
class image_Dataset(Dataset):
'''
roof data class
'''
def __init__(self, csv_file, transform = None):
'''
Args:
csv_file (string): Path to the csv file with annotations.
transform (callable, optional): Optional transform to be applied
on a sample.
'''
self.roof_frame = pd.read_csv(csv_file)
self.transform = transform
def __len__(self):
return len(self.roof_frame)
def __getitem__(self, idx):
if torch.is_tensor(idx):
idx = idx.tolist()
root_dir = self.roof_frame.iloc[idx,4]
pic = self.roof_frame.iloc[idx, 1]
label = self.roof_frame.iloc[idx, 3]
img_name = os.path.join(root_dir, pic)
image = Image.open(img_name)
policy = self.roof_frame.iloc[idx, 0]
sample = {'image': image, 'policy': policy, 'label':label}
if self.transform:
image = self.transform(image)
return image, label, policy
I took the following code snipped off of this forum but I’m not sure how to get the mean of each feature set per ID. Could anyone help with that code assuming the below snippet as an example? (note: I did not add anything from the tabular dataset yet to the below)
class SuperEncoder(nn.Module):
def __init__(self):
super(MyModel, self).__init__()
self.roofEncoder = nn.Sequential(
nn.Conv2d(3, 6, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(6, 12, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.dwellingEconder = nn.Sequential(
nn.Conv2d(1, 6, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(6, 12, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(2)
)
self.fc1 = nn.Linear(54*54*16, 1000)
self.fc2 = nn.Linear(54*54*16, 1000)
self.fc_out(x)
def forward(self, x1, x2):
x1 = self.roofEncoder(x1)
x1 = x1.view(x1.size(0), -1)
x1 = F.relu(self.fc1(x1))
x2 = self.dwellingEncoder(x2)
x2 = x2.view(x2.size(0), -1)
x2 = F.relu(self.fc2(x2))
# Concatenate in dim1 (feature dimension)
X = torch.concat((x1, x2), 1)
x = self.fc_out(x)
return self.log_softmax(X, dim=1)