30 epochs both CNN (pre trained ResNet) and RNN.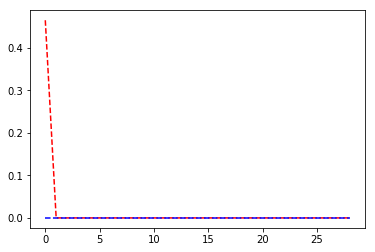
What are you currently plotting? Is it the loss of your train and validation set?
If so, could you plot the log of these values?
It looks like both are going down (to zero) pretty quickly. Why are you assuming your model suffers from vanishing gradients?
You could try to print out the norm of the gradients in a specific layer using torch.Tensor.register_hook.
yes it is the loss of train and validation.
Why is the validation loss parallel to the x -axis and training loss so quickly going down?
I want to understand what my model is suffering from?
can you give me an example of using register_hook during a training iteration?
How many train and validation samples are you using?
It looks like your model is perfectly fitting both sets.
Also, what kind of data are you using?
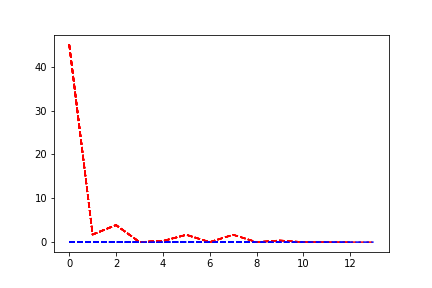
According to this plot
I am using 800 samples to train and 200 for validation
15 epochs
Its a baseline VQA model using pre-trained Resnet152 and LSTM cell.
Your loss range is quite different from the post before.
Could you additionally post the log of both losses?
It still looks like your validation loss just starts right away as zero, which seems to be a bug.
Could you post some sample inputs, targets and the corresponding predictions?
No. of data sample: 1000
[epoch: 1] train loss: 36090.254560, val loss= 1.757510
[epoch: 2] train loss: 1387.862027, val loss= 0.520770
[epoch: 3] train loss: 3111.286146, val loss= 0.439036
[epoch: 4] train loss: 17.947500, val loss= 0.137422
[epoch: 5] train loss: 203.278646, val loss= 0.066220
[epoch: 6] train loss: 1334.001943, val loss= 3.633866
[epoch: 7] train loss: 1.166515, val loss= 1.024039
[epoch: 8] train loss: 1342.652672, val loss= 0.007894
[epoch: 9] train loss: 6.536866, val loss= 1.497171
[epoch: 10] train loss: 300.237195, val loss= 0.191258
[epoch: 11] train loss: 0.371061, val loss= 0.164196
[epoch: 12] train loss: 1.507313, val loss= 0.133595
[epoch: 13] train loss: 0.239755, val loss= 0.096481
[epoch: 14] train loss: 0.156767, val loss= 0.000084
No. of data sample :5000
[epoch: 1] train loss: 64015.036718, val loss= 39.728265
[epoch: 2] train loss: 4630.669958, val loss= 88.093311
[epoch: 3] train loss: 1109.897145, val loss= 0.530974
[epoch: 4] train loss: 0.429050, val loss= 0.000138
[epoch: 5] train loss: 0.001611, val loss= 0.000000
[epoch: 6] train loss: 0.000000, val loss= 0.000000
[epoch: 7] train loss: 0.000000, val loss= 0.000000
[epoch: 8] train loss: 0.000000, val loss= 0.000000
[epoch: 9] train loss: 0.000000, val loss= 0.000000
[epoch: 10] train loss: 0.000000, val loss= 0.000000
[epoch: 11] train loss: 0.000000, val loss= 0.000000
[epoch: 12] train loss: 0.000000, val loss= 0.000000
[epoch: 13] train loss: 0.000000, val loss= 0.000000
[epoch: 14] train loss: 0.000000, val loss= 0.000000
Sample input is img tensor, question tensor, ans tensor
MSE answer loss is being calculated
Your model is perfectly fitting the data, so I don’t think you have a problem with vanishing gradients.
I would have a look at the validation data and check if you have a data leak somewhere, since I’m always skeptical about a zero loss for the validation data.
1 Like