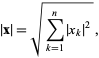In this article here: [1511.06394] Geodesics of learned representations, they describe using L2 pooling layers instead of max pooling or average pooling. The details of their implementation can be found under under 3.1:

I’m having trouble trying to figure out how to translate their equations to PyTorch, and I’m unsure as to how I would create a custom 2d pooling layer as well.
How do I implement this pooling layer in PyTorch?
I have the MaxPooling2d class rewritten like this:
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.nn.modules.utils import _pair, _quadruple
class MaxPool2d(torch.nn.Module):
def __init__(self, kernel_size=3, stride=1, padding=0):
super(MaxPool2d, self).__init__()
self.k = _pair(kernel_size)
self.stride = _pair(stride)
self.padding = _quadruple(padding)
def forward(self, x):
x = F.pad(x, self.padding, mode='reflect')
x = x.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
x = x.contiguous().view(x.size()[:4] + (-1,))
pool, indices = torch.max(x, dim=-1)
return pool
And based on that I create the L2 layer like this:
class L2Pool2d(torch.nn.Module):
def __init__(self, kernel_size=3, stride=1, padding=0):
super(L2Pool2d, self).__init__()
self.k = _pair(kernel_size)
self.stride = _pair(stride)
self.padding = _quadruple(padding)
def l2(self, x, constant=0, epsilon = 1e-6):
pool = torch.sum(x - constant, dim=-1)
return torch.sqrt(epsilon + pool)
def forward(self, x):
x = F.pad(x, self.padding, mode='reflect')
x = x.unfold(2, self.k[0], self.stride[0]).unfold(3, self.k[1], self.stride[1])
x = x.contiguous().view(x.size()[:4] + (-1,))
pool = self.l2(x)
return pool