gives me:
Traceback (most recent call last):
File “preprocess/kitti_maps.py”, line 108, in
local_map = voxelized.detach().clone() RuntimeError: CUDA error: global function call is not configured
I use:
Ubuntu 20.04
Device 0: “NVIDIA RTX A3000 Laptop GPU”
CUDA Driver Version / Runtime Version 11.6 / 11.6
I use conda environment python 3.7. Have installed CuPy for CUDA 11.6 and then installed the torch and torchvision as given here: PyTorch + CUDA 11.6
After this I installed the requirements.txt and following steps.
How can one debug such an issue. Am I using too recent pytorch and CUDA that its causing this problem?
The error is raised if no launch parameters were passed to the kernel launch, so I assume a function is running into a previous failure and the actual error message is wrong.
Could you post a minimal, executable code snippet reproducing the issue so that we could try to debug it, please?
Thanks. I will try to make the snippet. In the meantime I have a temporary workaround by computing the same on CPU. There is another problem with actual training now which I am checking
There is an another piece of code that is producing the exact same error. I dont know how to isolate the problem.
CUDA_LAUNCH_BLOCKING=1 python evaluate_iterative_single_CALIB.py with test_sequence=00 maps_folder=local_maps_0.1 data_folder=./KITTI_ODOMETRY/sequences/ weight="['./checkpoints/iter1.tar','./checkpoints/iter2.tar','./checkpoints/iter3.tar']"
WARNING - CMRNet-evaluate-iterative - No observers have been added to this run
INFO - CMRNet-evaluate-iterative - Running command 'main'
INFO - CMRNet-evaluate-iterative - Started
TEST SET - Not found: ./KITTI_ODOMETRY/sequences/test_RT_seq00_10.00_2.00.csv
Generating a new one
4541
0%| | 0/4541 [00:00<?, ?it/s]Init worker 0 with seed 610730943
Init worker 1 with seed 610730944
Init worker 2 with seed 610730945
Init worker 3 with seed 610730946
Init worker 4 with seed 610730947
Init worker 5 with seed 610730948
ERROR - CMRNet-evaluate-iterative - Failed after 0:00:03!
Traceback (most recent calls WITHOUT Sacred internals):
File "evaluate_iterative_single_CALIB.py", line 308, in main
rotated_point_cloud = rotate_forward(point_cloud, RT1)
File "/home/sxv1kor/Temp/CMRNet/utils.py", line 79, in rotate_forward
return rotate_points_torch(PC, R, T, inverse=True)
File "/home/sxv1kor/Temp/CMRNet/utils.py", line 46, in rotate_points_torch
RT = R.clone()
RuntimeError: CUDA error: __global__ function call is not configured
It seems to always happen when .clone() is called. Atleast that is what is common between the the errors.
Any ideas how to isolate the bug in this larger script that I am running ?
If I replace clone() with detach() then that error disappears strangely.
def rotate_points_torch(PC, R, T=None, inverse=True):
if T is not None:
R = quat2mat(R)
T = tvector2mat(T)
RT = torch.mm(T, R)
else:
#RT = R.clone()
RT = R.detach()
if inverse:
RT = RT.inverse()
In the code I have commented the RT = R.clone() and replaced with detach(). Now the error is as follows:
ERROR - CMRNet-evaluate-iterative - Failed after 0:00:03!
Traceback (most recent calls WITHOUT Sacred internals):
File "evaluate_iterative_single_CALIB.py", line 308, in main
rotated_point_cloud = rotate_forward(point_cloud, RT1)
File "/home/sxv1kor/Temp/CMRNet/utils.py", line 80, in rotate_forward
return rotate_points_torch(PC, R, T, inverse=True)
File "/home/sxv1kor/Temp/CMRNet/utils.py", line 49, in rotate_points_torch
RT = RT.inverse()
RuntimeError: CUDA error: __global__ function call is not configured
The error does not seem to have much with clone() function but something else…
The calling code is as follows:
R = quat2mat(target_rot[0])
T = tvector2mat(target_transl[0])
RT1_inv = torch.mm(T, R)
RT1 = RT1_inv.clone().inverse()
rotated_point_cloud = rotate_forward(point_cloud, RT1)
RTs = [RT1]
Yes, you are delaying the error report as was my previous speculation:
If no proper CUDA error checking is performed the next CUDA operation might be running into the “sticky” error and report the error message, so I think you are right that neither clone() nor inverse are the root cause of the issue but are just reporting “an error” as the CUDA context is corrupt.
Since I don’t know which call causes the issue in the first place (and doesn’t seem to properly report it) I would also not bet that the error message is actually correct.
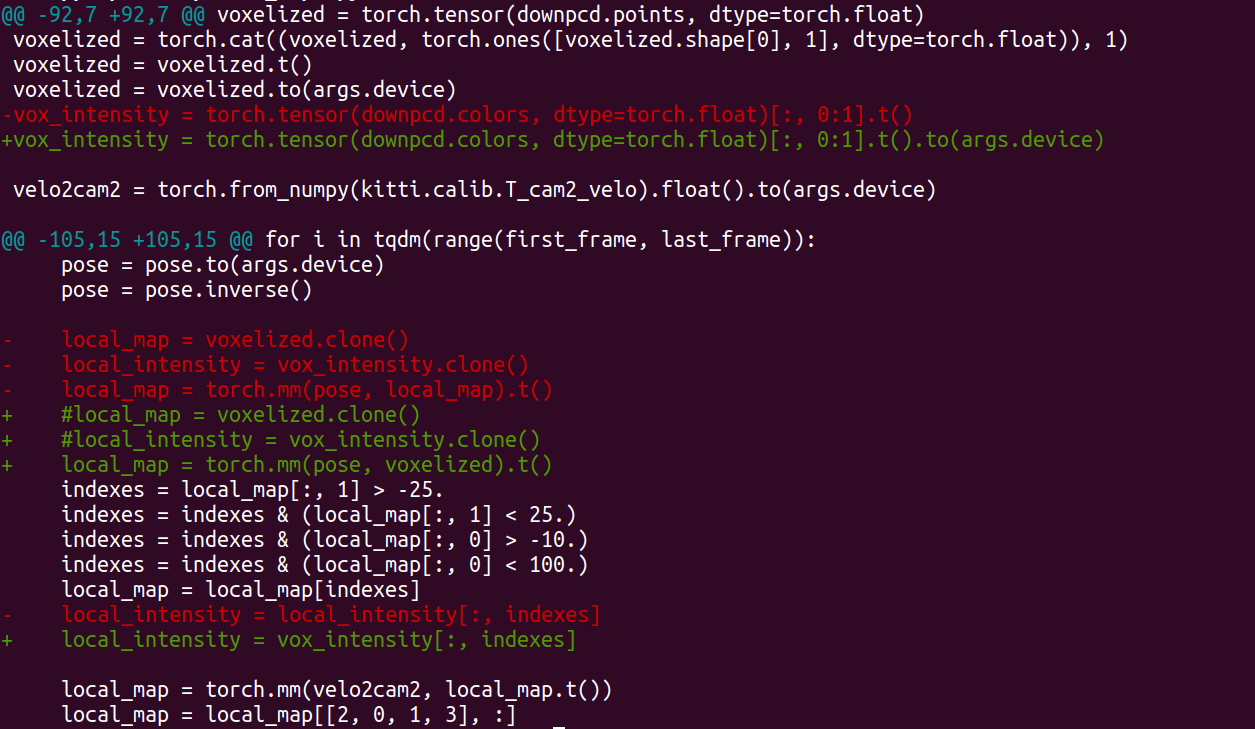
yes, could be. On the other hand, what I found with the previous (first) example of preprocess/kitti_maps.py, is that
if I eliminate the calls to .clone() method as given below, then the script runs fine on GPU (atleast On a Ubuntu 18.04 with CUDA 11.3 + matched PyTorch).
Try to come up with a minimal code snippet to reproduce the issue, as right now it seems that random operations are running into the error. I.e. even the cublas error could be caused by just running into an already corrupted CUDA context.