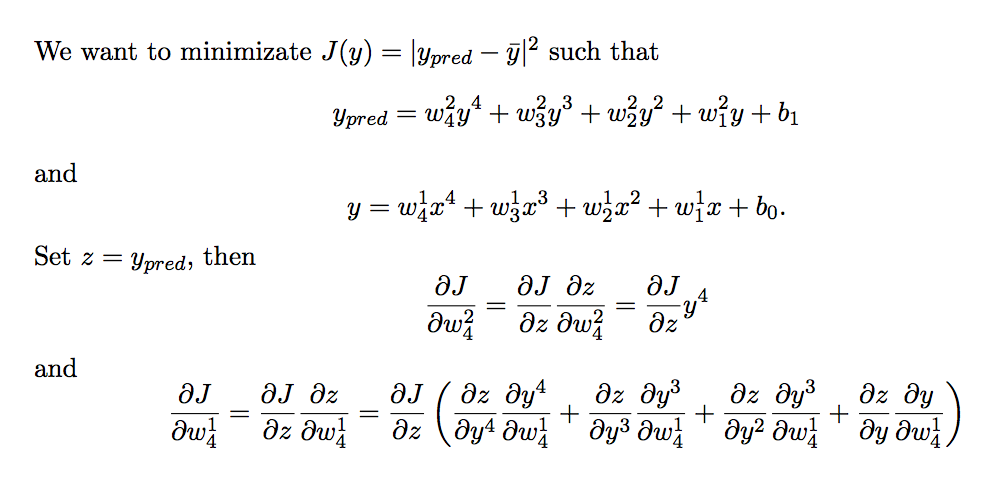I have downloaded a program from github: https://github.com/pytorch/examples/tree/master/regression .
The network has a single fully-connected layer to fit a 4th degree polynomial. Then I want to design a two layers network with the same construct to fit a more complicated function. But it could not work completely. Since I am a newer, could someone help me and give me some suggestion?
Firstly, let me say thank you to the author.
# !/usr/bin/env python
from __future__ import print_function
from itertools import count
import torch
import torch.autograd
import torch.nn.functional as F
from torch.autograd import Variable
# get the coefficient of the polynomial
POLY_DEGREE = 4
W_target = torch.randn(POLY_DEGREE, 1) * 5
b_target = torch.randn(1) * 5
# Builds features i.e. a matrix with columns [x, x^2, x^3, x^4]
def make_features(x):
x = x.unsqueeze(1)
return torch.cat([x ** i for i in range(1, POLY_DEGREE+1)], 1)
# generate polynomial
def f(x):
"""Approximated function."""
return x.mm(W_target) + b_target[0]
# Builds a batch i.e. (x, f(x)) pair.
def get_batch(batch_size=32):
random = torch.randn(batch_size)
x = make_features(random)
y = f(x)
return Variable(x), Variable(y)
# Define model: it is error!!!!!!
fc = torch.nn.Linear(W_target.size(0), 1)
x1 = make_features(fc.eval())
y1 = f(x1)
fc1 = torch.nn.Linear(W_target.size(0), 1)
for batch_idx in count(1):
# Get data with the Variable type
batch_x, batch_y = get_batch()
# Reset gradients
fc1.zero_grad()
# Forward pass
output = F.smooth_l1_loss(fc1(y1), batch_y)
# Backward pass
output.backward()
# Apply gradients
for param in fc.parameters():
param.data.add_(-0.1 * param.grad.data)
# Stop criterion
loss = output.data[0]
print(batch_idx, "is: ", loss)
if loss < 1e-3:
break
Hi matilu, not sure if it’s useful, but I made a video on forwardprop/backwardprop, chain rule, and corresponding pytorch code, not sure if it could be useful? There are a few parts, so you can just choose the part(s) that work for you. I’m doing it in context of rnn, but it’s probably generally applicable.