I wrote the following reinforcement learning code in PyTorch, TorchRL. This changes the total_frames and frames_per_batch, but the code is basically based on the PPO tutorial: Google colab
In addition, a 96x96x3 image was obtained from the InvertedDoublePendulum in order to obtain visual data of the environment in the training.
base_env = GymEnv("InvertedDoublePendulum-v4", device=device, frame_skip=frame_skip, from_pixels=True, pixels_only=False)
env = TransformedEnv(
base_env,
Compose(
ObservationNorm(in_keys=["observation"]),
PermuteTransform((-1, -3, -2), in_keys=["pixels"]),
Resize(96, 96),
PermuteTransform((-2, -1, -3), in_keys=["pixels"]),
ToTensorImage(),
DoubleToFloat(),
StepCounter(),
),
)
This programme eats up memory as soon as it runs and is forced to terminate. And this eats up even 50 GB of RAM. I suspect this is because SyncDataCollector is dealing with pixel data.
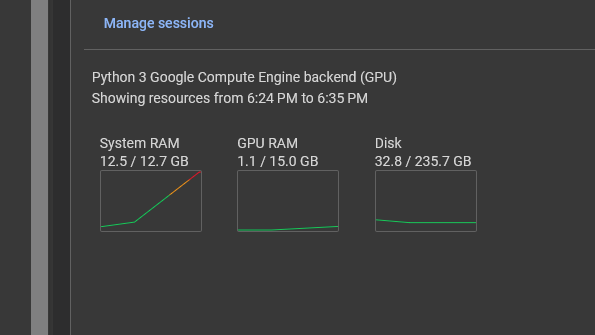
However, image data is essential for me, so removing the from_pixels option is unthinkable. The total_frames is also necessary because if the total number of frames is reduced, the learning process is not completely finished. Changing the image size will sooner or later eat up RAM.
I need to save or free the RAM somehow. Do you have any ideas?

