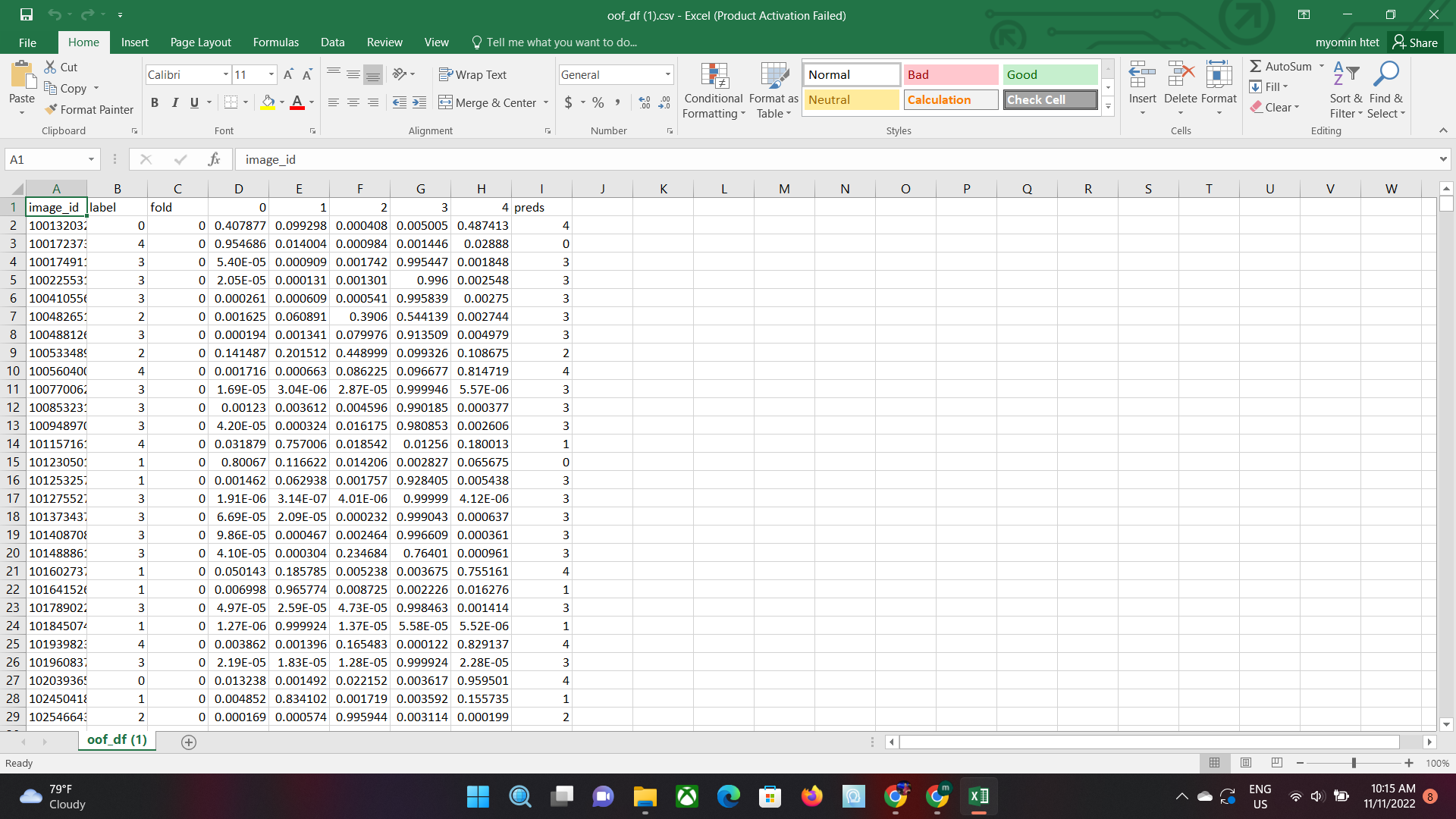
Here is the ideal type.
I used stratified K fold and I don’t know how to put prediction data into a Dataframe
Here is the code
for fold, (train_index, val_index) in enumerate(Fold.split(folds, folds[‘label’])):
train_df = folds.loc[train_index].reset_index(drop=True)
val_df = folds.loc[val_index].reset_index(drop=True)
train_dataset = TrainDataset(train_df, transform = train_transform)
valid_dataset = TrainDataset(val_df, transform = valid_transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=32, shuffle=False, num_workers=4, pin_memory=True)
with torch.enable_grad():
for epoch in range(epochs):
model.to(device)
model.train()
train_loss = 0.0
train_accuracy = 0.0
loop1 = tqdm(train_loader)
for image, label in loop1:
image = image.to(device)
label = label.to(device)
preds = model(image)
loss = criterion(preds, label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_accuracy += get_score(label.cpu().detach().numpy(), preds.argmax(1).cpu().detach().numpy())
loop1.set_description(f'EPOCH: {epoch+1}/{epochs} TRAIN')
loop1.set_postfix(TRAIN_AUC = train_accuracy/len(train_loader) , TRAIN_LOSS = train_loss/len(train_loader))
with torch.no_grad():
valid_loss = 0.0
num_corrects = 0.0
valid_accuracy = 0.0
preds = []
model.eval()
loop2 = tqdm(valid_loader)
for x, y in loop2:
x = x.to(device)
y = y.to(device)
output = model(x)
loss = criterion(output, y)
valid_loss += loss.item()
predictions = output.argmax(1)
preds.append(predictions.cpu().detach().numpy())
valid_accuracy += get_score(y.cpu().detach().numpy(), output.argmax(1).cpu().detach().numpy())
loop2.set_description(f'EPOCH: {epoch+1}/{epochs} VALID')
loop2.set_postfix(VAL_AUC = valid_accuracy/len(valid_loader) , VAL_LOSS = valid_loss/len(valid_loader))