I’m trying to implement this paper Two-Stream FCNs to Balance Content and Style for Style Transfer, and here’s a picture of the architecture:
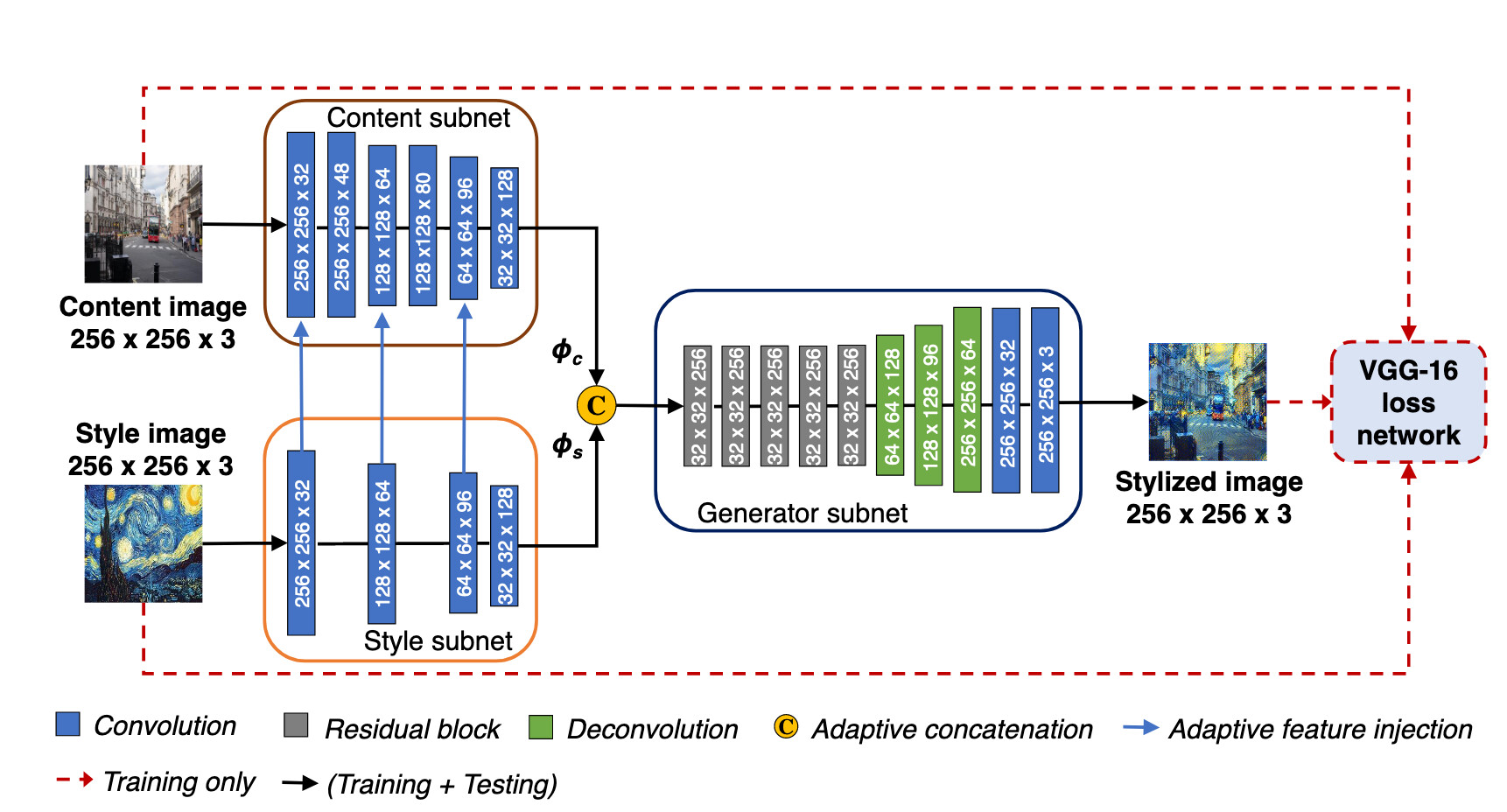
The outputs of the content and style subnets are fed into the generator subnet.
The content subnet’s loss depends on the generator subnet’s output and the input content image, and the style subnet’s loss depends on the generator subnet’s output and the input style image.
But the generator’s loss is a linear combination of the style and content loss.
The paper mentions training the networks simultaneously and updating each of the weights independently.
How would I go about training these networks simultaneously?
I’ve defined the optimizers and criterions of the 3 subnets. From my outputs the networks only seems to be learning the style of the style image. Is this the wrong approach?
for i in range(epochs):
for xs, _ in train_dataloader:
s_optimizer.zero_grad()
c_optimizer.zero_grad()
g_optimizer.zero_grad()
s_image, p1, p2, p3 = s_model(style_image)
c_image = c_model(xs.to(device), gamma, p1, p2, p3)
generated_images = g_model(c_image.clone(), s_image.clone(), gamma)
# use pretrained vgg as a feature extractor
generated_outputs = VGG(generated_images)
style_loss = s_criterion(generated_outputs, style_image)
content_loss = c_criterion(generated_images, xs.to(device))
generator_loss = g_criterion(style_loss, content_loss)
generator_loss.backward(retain_graph = True)
style_loss.backward(retain_graph = True)
content_loss.backward()
g_optimizer.step()
c_optimizer.step()
s_optimizer.step()